&Notepad
"Do What I Mean": Name Resolution in Programming Languages
Abstraction through names is a fundamental building block of any programming language. Names, or variables, serve as placeholders which permit a piece of code to abstract over its inputs until the name is resolved.
// Concrete code (sum to 10)
let sum = 0;
for (let i = 1; i <= 10; ++i) {
sum += i;
}
// Abstract code (sum to N)
function sum_to(N) {
let sum = 0;
for (let i = 1; i <= N; ++i) {
sum += i;
}
return sum;
}
The process of name resolution is the question: when should a name be given a value, and which value should it be? In the above example, it’s simple: when I call sum_to(10), the name N means 10. However, conflict arises when multiple values could apply to a given name. For example, if I typo’d the sum variable:
function sum_to(N) {
let N = 0;
for (let i = 1; i <= N; ++i) {
N += i;
}
return N;
}
Then what happens? Or a better question: what should happen? This is the core challenge of name resolution, is determining a means of resolving conflicts in a sensible way. In this note, I’m going to explore what “sensible” name resolution means in a few different areas of programming languages, showing along the way that seemingly disparate language features share similar problems.
1. Variable scope
The simplest and most canonical example of name resolution is variable scoping, or mapping variables to values. For example, consider this program1:
let x = 1;
function g(z) { return x + z; }
function f(y) {
let x = y + 1;
return g(y * x);
}
console.log(f(3));
When executing the inner g function, it has the following call stack:
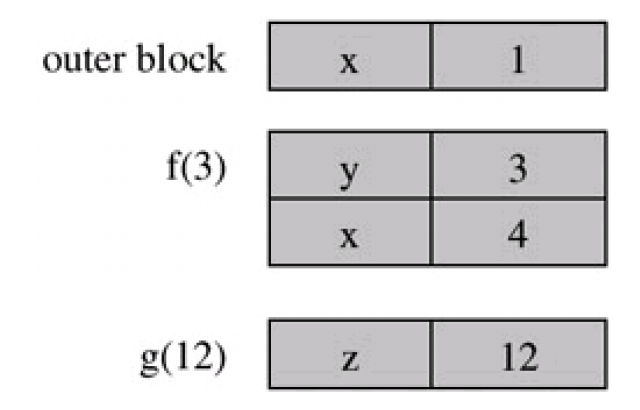
Take a second to walk through the code and verify this diagram matches your expectations. When executing g, the name resolution question here is: in the expression x + z what does x refer to? There are two options: the x defined in the top-level scope, and the x defined in the function f.
The first option, picking x = 1, is called lexical scoping. The intuition behind lexical scoping is that the program structure defines a series of “scopes” that we can infer just by reading the program, without actually running the code.
// The {N, ...} syntax indicates which scopes are "active" a given
// point in the program.
// BEGIN SCOPE 1 -- {1}
let x = 1;
function g(z) {
// BEGIN SCOPE 2 -- {1, 2}
return x + z;
// END SCOPE 2
}
function f(y) {
// BEGIN SCOPE -- {1, 3}
let x = y + 1;
return g(y * x);
// END SCOPE
}
console.log(f(3));
// END SCOPE 1
The nested structure of our program implies that at any line, we have a stack of scopes as annotated in the program above. To resolve a name, we walk the stack and search for the closest declaration of our desired variable. In the example, because scope 3 is not in the stack of scope 2, x + z resolves to the binding of x in scope 1, not scope 3.
Again, we call this “lexical” scoping because the scope stack is determined statically from the program source code (i.e. at compile-time, before the program is executed). The alternative approach, the one that resolves to x = 4, is called dynamic scoping. Recall our call stack above:
As you may have inferred at this point, dynamic scoping looks at the runtime call stack to find the most recent declaration of x and uses that value. Here, the binding x = 4 in f is more recent than the binding x = 1 in the top-level scope.
In both cases, dynamic or lexical, the core algorithm is the same: given a stack of scopes, walk up the stack to find the most recent name declaration. The only difference is whether the the scope stack is determined at compile-time or at run-time.
So which scoping method is preferable? Judging by popularity, lexical scoping has won the war. The vast majority of programming languages, Javascript included, use lexical scoping2. Generally, the pro-lexical arguments are:
- Unbound variable errors can be caught at compile time. If you typo a variable name, then the program can be checked for this issue before execution.
- “Spooky action at a distance”: with dynamic scoping, name bindings in very different parts of the program can affect your local implementation.
Few languages today make any serious attempt at having dynamic scoping, usually just flavors of Lisp. However, the arguments for dynamic scoping raise important concerns about limitations of lexical scoping. “The Art of the Interpreter” (Steele and Sussman, 1978, p.43-45) and “EMACS: The Extensible, Customizable Display Editor” (Stallman, 1981) lay out the essential arguments. Quoting Stallman:
Some language designers believe that dynamic binding should be avoided, and explicit argument passing should be used instead. Imagine that function A binds the variable FOO, and calls the function B, which calls the function C, and C uses the value of FOO. Supposedly A should pass the value as an argument to B, which should pass it as an argument to C.
This cannot be done in an extensible system, however, because the author of the system cannot know what all the parameters will be. Imagine that the functions A and C are part of a user extension, while B is part of the standard system. The variable FOO does not exist in the standard system; it is part of the extension. To use explicit argument passing would require adding a new argument to B, which means rewriting B and everything that calls B. In the most common case, B is the editor command dispatcher loop, which is called from an awful number of places.
What’s worse, C must also be passed an additional argument. B doesn’t refer to C by name (C did not exist when B was written). It probably finds a pointer to C in the command dispatch table. This means that the same call which sometimes calls C might equally well call any editor command definition. So all the editing commands must be rewritten to accept and ignore the additional argument. By now, none of the original system is left!
While lexical scoping proponents argue that their scheme improves modularity by limiting cross-module effects (names can’t be unexpectedly bound outside of their module), Stallman here advocates that dynamic scoping also improves modularity. In the natural course of software design, dynamic scoping improves the separation of concerns by not requiring the creators of middleware to know all the parameters that need to pass down through their interface.
To my knowledge, however, no formal study has ever been done on the impact/usability of lexical vs. dynamic scoping. And since dynamic scoping never really caught on, it’s difficult beyond anecdotal experience to say how true arguments on either side are.
2. Control flow
This core idea of walking stacks to find names comes up in a surprising number of places in programming langauge design. You’ve probably seen a language that has labels to allow breaking out of arbitrarily nested loops. Here’s an example in Rust:
'outer: for i in 1 .. 10 {
'inner: for j in 1 .. 10 {
if i == j {
break 'outer;
}
}
}
This is an example of a lexically scoped jump—to determine what label outer refers to, we walk up the “label scope” stack (at compile time) to find the closest definition of outer3. What would a dynamically scoped jump look like? Here’s an imaginary language:
def div(m, n) {
if n == 0 {
break error("Div by 0");
}
return m / n;
}
def main() {
let x = div(5, 3);
let y = div(x, 0);
print("Success!", y);
return;
error(s) {
print("Error", s);
}
}
Here, the idea is that the div function uses a dynamically-scoped label error to jump to if the function fails. That error label could be anywhere on the call stack above the div function. This might sound familiar, because this is how exceptions work! Here’s an actual example in OCaml:
exception Error of string
let div m n =
if n = 0 then
raise (Error "Div by 0")
else
m / n
let main () =
try
let x = div 5 3 in
let y = div x 0 in
Printf.printf "Success: %d" y
with Error s ->
Printf.printf "Error: %s" s
let () = main () (* Prints "Error: Div by 0" *)
A raise is a control flow mechanism that relies on dynamically-scoped labels, or try blocks. One point this shows is that both lexical and dynamic jumps seem useful, and some languages do incorporate variants of both. It is possible for lexical/dynamic scoping to co-exist, at least for control flow.
Interestingly, the arguments against dynamic scoping for labels are somewhat the inverse of the arguments against dynamic scope for variables. A library that relies on dynamically scoped variables is concerned with outside modules accidentally modifying its state, while outside modules are concerned with their libraries raising exceptions that leave the library.
3. Method resolution with OOP
A common issue in programming is associating functions with data. In languages like C, this is often done via convention in function naming.
typedef struct {
int* data;
int len;
} stack_t;
stack_t* stack_new();
void stack_push(stack_t* stack, int value);
int stack_pop(stack_t* stack);
int main() {
stack_t* stack = stack_new();
stack_push(stack, 3);
printf("%d", stack_pop(stack));
return 0;
}
Even in more modern languages like OCaml, this is still basically how function/data associations work.
module type Stack = sig
type t
val make : () -> t
val push : t -> int -> t
val pop : t -> int * t
end
let s = Stack.make () in
let s = Stack.push s 3 in
let (n, _) = Stack.pop s in
Printf.printf "%d" n
Most other modern languages, particularly object-oriented languages, use type-directed name resolution to use functions associated with data. For example, in Python:
class A:
def save(self): pass
a = A()
a.save() # Resolves to A.save(a)
Here, because a is of type A, when we try to call functions on a, the runtime can determine that the a.save function should refer to A.save. Object-oriented languages also support inheritance, which complicates name resolution:
class A:
def save(self): pass
def to_string(self): pass
class B(A):
def to_string(self): pass
b = B()
b.to_string() # resolves to B.to_string(b)
b.save() # resolves to A.save(b)
Conceptually, single-inheritance represents a stack of methods. When asking for a particular method, resolving the method involves walking the stack of methods for the closest declaration4 (this should sound familiar). Here, to_string resolves to the closest declaration in B, while save resolves to the closest declaration in A.
The hard part here is that while single-inheritance represents a stack, which has a clear means of resolving names (walk the stack for the closest name), multiple-inheritance turns this problem into a directed acyclic graph (DAG). Quoting from Guido’s post on the history of Method Resolution Order in Python:
Classic classes used a simple MRO scheme: when looking up a method, base classes were searched using a simple depth-first left-to-right scheme. The first matching object found during this search would be returned. For example, consider these classes:
class A:
def save(self): pass
class B(A): pass
class C:
def save(self): pass
class D(B, C): pass
If we created an instance x of class D, the classic method resolution order would order the classes as D, B, A, C. Thus, a search for the method x.save() would produce A.save() (and not C.save()). This scheme works fine for simple cases, but has problems that become apparent when one considers more complicated uses of multiple inheritance. One problem concerns method lookup under “diamond inheritance.” For example:
class A:
def save(self): pass
class B(A): pass
class C(A):
def save(self): pass
class D(B, C): pass
Here, class D inherits from B and C, both of which inherit from class A. Using the classic MRO, methods would be found by searching the classes in the order D, B, A, C, A. Thus, a reference to x.save() will call A.save() as before. However, this is unlikely what you want in this case! Since both B and C inherit from A, one can argue that the redefined method C.save() is actually the method that you want to call, since it can be viewed as being “more specialized” than the method in A (in fact, it probably calls A.save() anyways). For instance, if the save() method is being used to save the state of an object, not calling C.save() would break the program since the state of C would be ignored.
So how do we fix this problem? The core idea is that we want to turn this hard problem (name resolution on a DAG of classes) into an easy problem (name resolution on a stack of classes). This process is called “linearization”. The desirable properties of a linearization algorithm, as well as the actual algorithms used, are too much to discuss here. If you want to know more, you should read A Monotonic Superclass Linearization for Dylan (Barrett et al. 1996) which defines both the problem setting and the specific algorithm (“C3”) that Python today uses.
4. Method resolution with traits
Traits are an alternative approach to function/data association that have come into vogue in the last decade, most notably in Rust. They support the general notion of composition over inheritance, allowing functionality for a given data type to be broken up into multiple small chunks. For example:
pub struct Point { x: f32, y: f32 }
// Methods in this "impl block" are directly associated with the Point
// data type, no traits involved.
impl Point {
pub fn new(x: f32, y: f32) -> Point {
Point { x, y }
}
pub fn print(&self) {
println!("({}, {})", self.x, self.y);
}
}
pub trait Add {
// Self is a keyword referring to "the type implementing the trait"
fn add(&self, other: &Self) -> Self;
}
impl Add for Point {
fn add(&self, other: &Point) -> Point {
Point { x: self.x + other.x, y: self.y + other.y }
}
}
For methods in the initial impl Point block, method resolution is simple. If a particular value is known to be a Point, then calling .print() will always resolve to the Point::print function (these are called “inherent” methods).
use point::Point;
fn main() {
let p1 = Point::new(1.0, 2.0);
p1.print();
}
However, if we then try to use the add method:
use point::Point;
fn main() {
let p1 = Point::new(1.0, 2.0);
let p2 = Point::new(3.0, 4.0);
let p3 = p1.add(&p2);
}
We will get the error:
error[E0599]: no method named `add` found for type `point::Point` in the current scope
--> test.rs:32:15
|
2 | pub struct Point { x: f32, y: f32 }
| ---------------- method `add` not found for this
...
32 | let p3 = p1.add(&p2);
| ^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following trait is implemented but not in scope, perhaps add a `use` for it:
|
27 | use point::Add;
|
Method resolution for traits has two steps: first the trait has to be imported (the use keyword) into the current scope, and then the type system has to resolve the method name to the implementation of a corresponding trait. In the above example, this will work:
use point::{Point, Add};
fn main() {
let p1 = Point::new(1.0, 2.0);
let p2 = Point::new(3.0, 4.0);
let p3 = p1.add(&p2);
}
Importing the trait is important because multiple traits could provide implementations of methods with the same name. For example, if add were also part of another trait:
pub trait Add {
fn add(&self, other: &Self) -> Self;
}
pub trait Arithmetic {
fn add(&self, other: &Self) -> Self;
fn sub(&self, other: &Self) -> Self;
}
impl Add for Point { .. }
impl Arithmetic for Point { .. }
Then in order to know which add method a p.add(..) refers to, exactly one of those traits must be imported into the current scope.
The second step, resolving the name to a trait, is simple in the example above. An example algorithm would be to enumerate all implemented traits for Point in scope, then linear search through each trait for a method that matches the desired name and type signature. However, complications arise around generics. For example:
pub struct Vec2<T> { x: T, y: T }
impl<T> Add for Vec2<T> where T: Add {
fn add(&self, other: &Vec2<T>) -> Vec2<T> {
Vec2 { x: self.x.add(&other.x), y: self.y.add(&other.y) }
}
}
Above, we have a generic vector of two elements, and we again implement the Add trait, except this time our implementation is conditional—Vec2 only implements Add when its element type T implements Add. When we use the vector:
fn main() {
let p1: Vec2<i32> = Vec2::new(1, 2);
let p2: Vec2<i32> = Vec2::new(3, 4);
let p3 = p1.add(&p2);
}
In order to resolve add, the compiler has to prove that i32: Add (i.e. there exists something that implements Add for i32). To solve a name resolution problem this complex, Rust internally has an entire logic programming language dedicated to it.
An important constraint on this problem is that two traits are not allowed to possibly implement the same method for the same data type. Little Orphan Impls covers the gory details here, but the key idea is that Rust wants to ensure that importing a crate or a type doesn’t suddenly cause your program to change because you’re accidentally using a different trait implementation than before.
However, this isn’t ideal because it can be useful to have more “general” implementations of a method for every type, and more “specific” implementations of a method for a few types, e.g. a general vs. customized to_string method. Hence, a major project in the Rust pipeline is trait specialization, as detailed in Sound and ergonomic specialization for Rust. The challenge is to determine what makes a method “specific” vs. “general,” which is still being debated in the community.
Overall, Rust’s approach to method resolution is trying to implement a maximally flexible means of associating functionality to data, and approaching a “do what I mean” algorithm for resolving methods. The trade off is the complexity in the trait resolution algorithm, and the extent to which that complexity is passed on to the user instead of hidden in the compiler.
5. Specificity
While Rust has yet to settle on a notion of “specificity” for functions, CSS, the web-based style description language, has a first-class notion of specificity baked into its semantics. CSS enables users to define rules that change the visual properties of UI elements. For example, if I have the HTML:
<span id="foo" class="bar">The text</span>
This span tag has some visual properties, like a text color and a font-size. The core algorithm in a CSS engine is to determine, given an HTML element and a set of CSS rules, the values of each visual property. For example, if our CSS is:
/* All span tags */
span {
font-size: 10px;
color: blue;
}
/* All tags with id "foo" */
#foo {
color: red;
}
/* All span tags with class "bar" */
span.bar {
font-size: 12px;
color: green;
}
Then what should the value of font-size and color be? Intuitively, for each property, we want to pick the “most specific” rule that applies to our tag and provides that property. The specificity rules are surprisingly simple (quoting the CSS Specification):
A selector’s specificity is calculated for a given element as follows:
- count the number of ID selectors in the selector (= A)
- count the number of class selectors, attributes selectors, and pseudo-classes in the selector (= B)
- count the number of type selectors and pseudo-elements in the selector (= C)
- ignore the universal selector
Specificities are compared by comparing the three components in order: the specificity with a larger A value is more specific; if the two A values are tied, then the specificity with a larger B value is more specific; if the two B values are also tied, then the specificity with a larger C value is more specific; if all the values are tied, the two specificities are equal.
In our example above, we have:
span (A=0, B=0, C=1)
#foo (A=1, B=0, C=0)
span.bar (A=0, B=1, C=1)
This means that the precedence order is #foo > span.bar > span. Correspondingly, our span then will have a color: red (from #foo) and a font-size: 12px (from span.bar).
In a way, you can think about this as a kind of lexical scoping. Variables use the stack-based syntax of the language to define a stack of lexical scopes, or the runtime stack to define a stack of dynamic scopes. In CSS, for a given UI element, a specificity value can be statically computed for each CSS rule, which forms a “stack” of rules (or ordered scopes). After filtering out rules that don’t apply to the element, the value of each visual property is computed by walking up the rule stack to find the closest binding.
Conclusion
Name resolution is a hard problem that shows up in many aspects of programming languages: variables, jumps, methods, and so on. A core idea is that most naming conflicts can be reduced to a stack of scopes (where “scope” could be a code block, a class definition, a CSS rule, etc.), and name resolution is walking up the scope stack. The hard part is instead what defines your stack: static vs. dynamic scopes for variables, linearization methods for classes, specificity heuristics for CSS rules.
A major tradeoff for name resolution systems is the level of complexity. More complex resolution systems like Rust’s traits or CSS’s rule specificity approach the “do what I mean” ideal where the user has to minimally disambiguate names/scopes. However, debugging naming issues with complex resolution can be difficult—every CSS programmer knows the shame of decorating rules with !important.
I would love to see a more unified theory of name resolution be applied to uniformly understand and solve the issues raised above. We also need more studies to understand what name resolution systems maximize productivity as a function of intuitiveness, error-proneness, and debuggability.
If you have comments, please send them my way at wcrichto@cs.stanford.edu or leave them on Hacker News.
P.S. A few folk have pointed out that Perl 6 has a good number of the features above. Also that there’s been recent work on a theory of name resolution.
-
Example and diagram taken from Concepts in Programming Languages. ↩
-
Some languages have more complex scoping mechanisms like Python’s LEGB scoping, but usually they’re bastardized variants of lexical scoping. ↩
-
This is basically how control flow in WebAssembly works. ↩
-
I highly recommend implementing an inheritance mechanism in Lua to gain an appreciation for how this works concretely. ↩