Writeup
Summary
We created a high-level Lua/Terra API which uses CUDA to execute Terra functions on the GPU. Our API can translate arbitrary Terra code to CUDA code and handles all device memory management and similar issues behind the scenes.
Background
Writing GPU code is time-consuming. CUDA, the best available language for GPU programming, requires a lot of work from the programmer in order to do even simple tasks. The programmer must remember to keep host memory and device memory in sync. He must calculate the number of threads and warps he needs (and the term "warp" is quite confusing if you haven't heard it before). He must calculate for himself the appropriate index at each instance of his kernel. And most importantly, he can only write GPU code in CUDA!
Some APIs like PyCUDA and JCuda have attempted to tackle this problem. Unfortunately, they only address the last point raised above—one can use CUDA functions in the course of writing a Python program, but it is neither easy nor intuitive. In PyCUDA, for example, one must actually embed CUDA code as a string inside of the Python program. Terracuda's goal is to abstract away all these issues and let the programmer write GPU code at his convenience.
Approach
Lua is a fast, lightweight, and embeddable scripting language found in places like Wikipedia, World of Warcraft, Photoshop Lightroom, and more. Lua's simple syntax and dynamic typing also make it an ideal language for novice programmers. Terra is a language embedded in Lua which gives easier access to low-level functions (e.g. malloc).
Terra has a few key features we used: it JIT-compiles to LLVM, it interoperates with Lua, and its types are treated as values in Lua. This combined with the recent release of NVIDIA's NVPTX LLVM backend means that we can easily translate between Terra code and CUDA code. Its interoperation means that any Lua value can be used in Terra code, and its type system means that Lua can generate dynamic types on the fly.
Before we delve into the specifics of the API, let's look at a sample implementation of the SAXPY routine in regular Lua and using Terracuda.
local P, N = {X = {}, Y = {}, a = 2.0}, 1000
-- populate X and Y
for i = 1, N do
P.Y[i] = P.a * P.X[i] + P.Y[i]
endlocal P, N = {X = {}, Y = {}, a = 2.0}, 1000
-- populate X and Y
local ptype = cudalib.make_struct_type(P)
local saxpy = cudalib.make_kernel(
terra(p : &ptype, i : int)
p.Y[i] = p.a * p.X[i] + p.Y[i]
end)
saxpy(P, N)Both pieces of code above will produce the same output (i.e. P.C will contain the correct values). You may notice, however, that device memory, thread indexing, kernel calls, etc. are all conspicuously absent from the Terracuda code. This is all handled by the API. Here's how it works: consider that you have some table P and a Terra function F that operates on P which you want to convert to GPU code. The process is as follows:
- Run
make_struct_type(P). Because Terra types are Lua values, Lua can loop throughPand generate a newstructtype that corresponds exactly with the given input. So in the aboveSAXPYexample, the generated type isstruct P { X: &int, Y: &int, a: double }. - Run
make_kernel(F). This pre-allocates device memory for every entry inside the struct if possible (the exception being if we have variable length arrays). Then, it JIT-compilesFto CUDA code for later use. Lastly,make_kernelreturns a closure over these values which will copy the input into the allocated device memory, run the kernel on the device parameters, and copy the modified memory back to the host. - Run the result of
make_kernelwith your input parameters as well as the number of threadsNto create.
This approach gives great freedom to Terracuda users, as essentially any CUDA program can be translated to Terracuda without much trouble. Note that Terracuda is not purely data-parallel—you can run your kernel over any number of threads with any input! Initially, we wrote the API just in terms of data-parallel primitives like map and reduce, but over time as we learned more about Terra we realized that it empowers us to write more flexible code, and consequently we added more features to the API like struct type creation. For example, matrix multiply looks like this:
local P = {A = {}, B = {}, C = {}, N = 1000}
-- populate A and B
local stype = cuda.make_struct_type(P)
local kernel = cuda.make_kernel(
terra(p : &stype, idx : int)
var i, j, sum = idx / p.N, idx % p.N, 0
for k = 0, p.N do
sum = sum + p.A[i * p.N + k] * p.B[k * p.N + j]
end
p.C[idx] = sum
end)
kernel(P, P.N * P.N)For comparison, the map map primitive looked similar but granted less flexibility. It looked like this:
local A = {}
-- populate A with integers
local kernel = cuda.map(terra(x : int) : int
return x + 1
end)
kernel(A)That's the basics of the API. You can find the source for the API here: https://github.com/willcrichton/terracuda
Results
The API itself works great, so we concerned ourselves mostly with performance and concision when considering results. We wrote a myriad of applications in C, CUDA, Terra, and Terracuda ranging from SAXPY to a circle renderer we wrote for class. For each application, we sampled execution time and also recorded the size of the codebase required for the CUDA implementation versus the Terracuda one. All code was tested on a Mid-2012 Macbook Pro with an NVIDIA GTX 480 GPU. Each program used the input size listed. We found the following execution times:
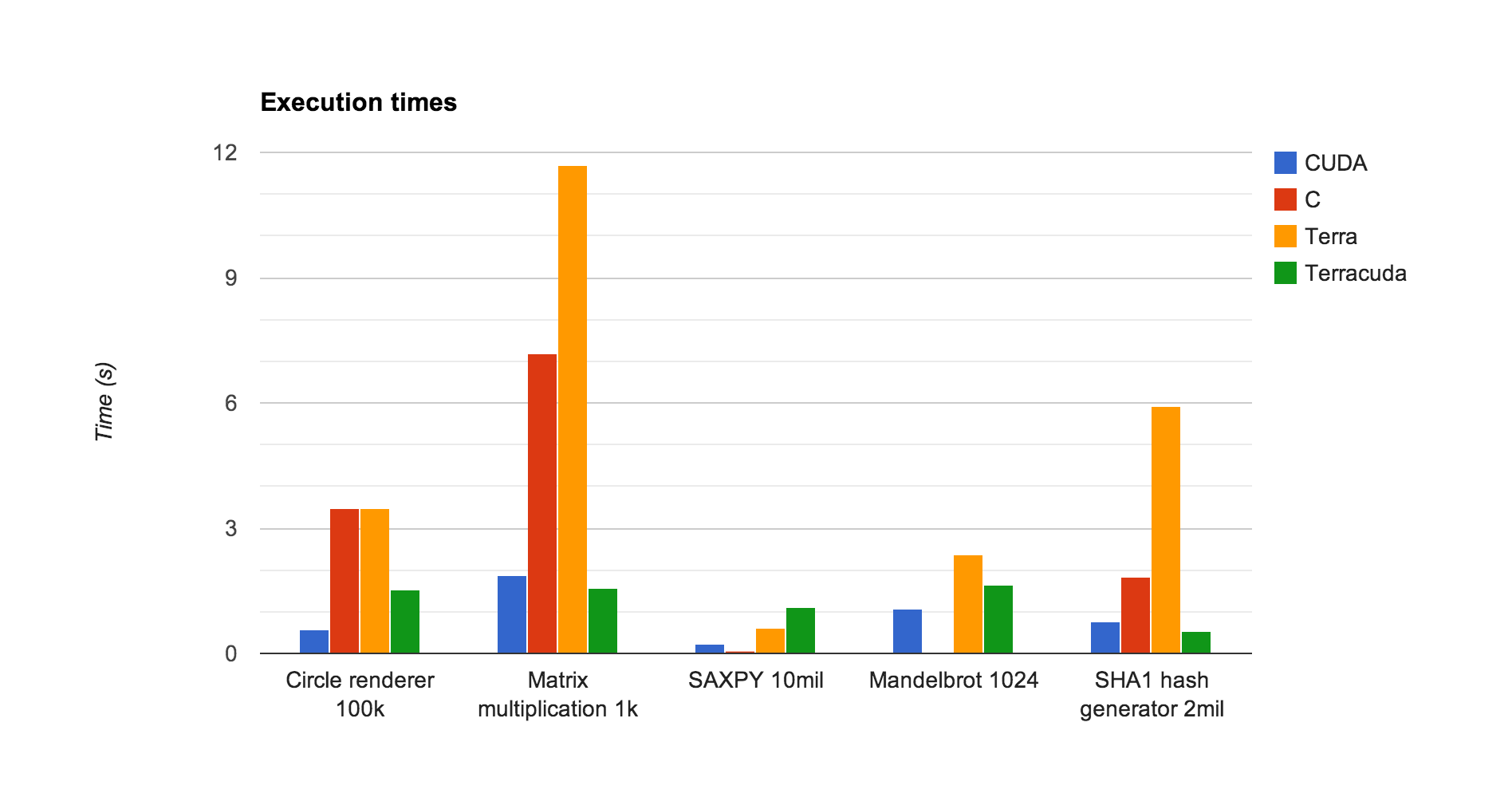
So far, Terracuda (despite being JIT-compiled in a dynamically typed language) is mostly competitive with C and CUDA. In some cases, like with matrix multiplication, it actually performs better than hand-written CUDA! It doesn't work as well, however, on simple programs like SAXPY as the overhead of compiling/spinning up a kernel is greater than any performance gains. It's worth noting that Terracuda spends, on average, about 3x as much time booting up its kernel than CUDA, primarily because CUDA programs are precompiled and Terracuda is JIT-compiled, so our API does bring greater overhead (noticeable in the poor results for SAXPY).
Experience leads us to believe that the remaining difference between Terracuda and CUDA could be eliminated by implementing support for constant and shared memory annotations. The circle renderer, for example, has a loop over a set of circles that updates an array data for every circle. By switching the updates to data with a temporary array not in global memory which gets copied at the end, we found a 45% decrease in execution time in the Terracuda implementation (from about 2.3s to 1.5s). However, arrays like position and radius are still stored in global memory (as opposed to constant memory as is used in the CUDA version), so CUDA still beats out Terracuda on the circle renderer.
Terracuda also performs better than the CUDA SHA1 hash generator we wrote, and while promising, doesn't necessarily mean we expect Terracuda to be faster than CUDA. Due to time constraints, the CUDA SHA1 code we wrote could be made more efficient by perhaps utilizing shared or constant memory on the GPU.
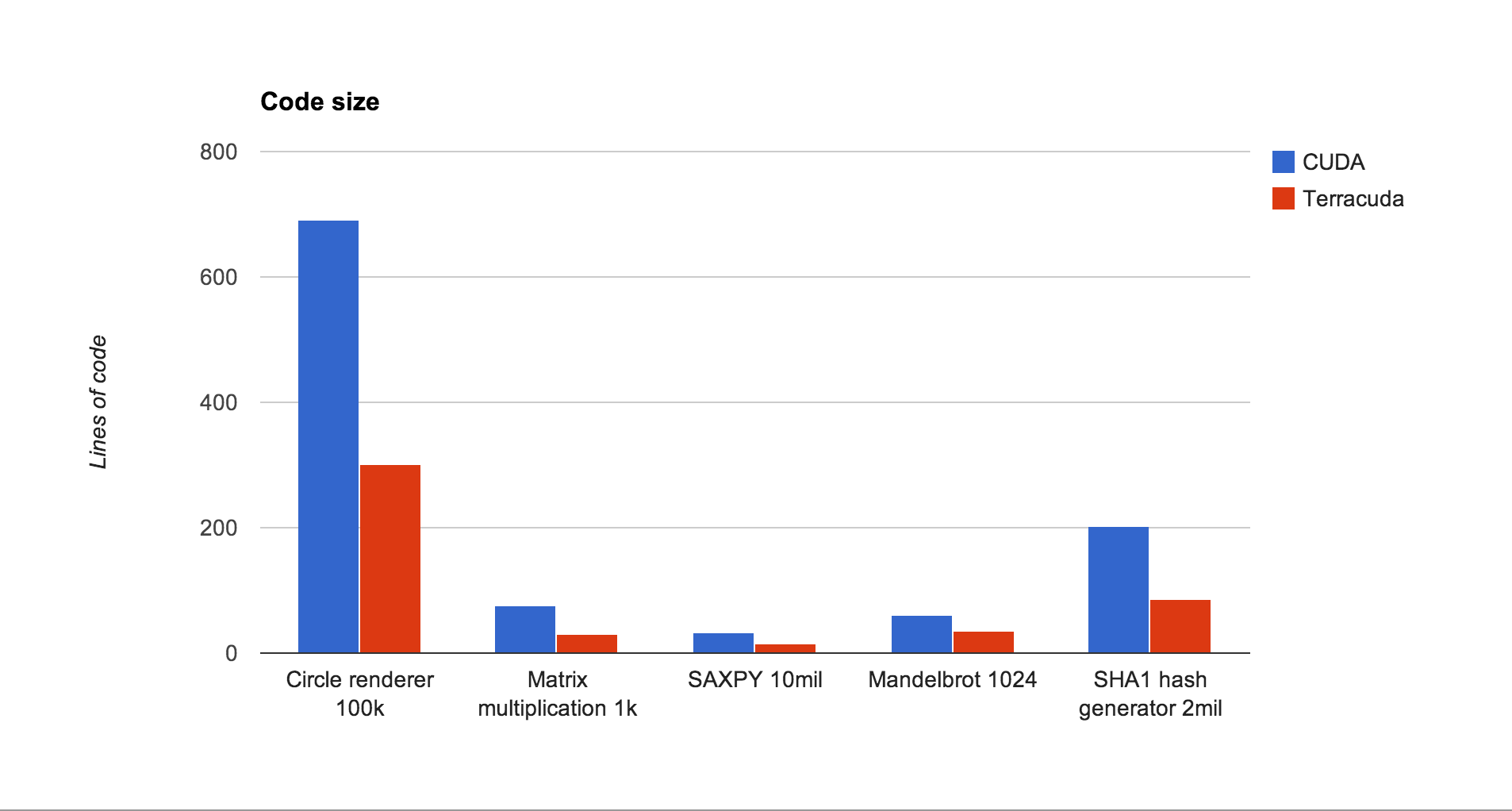
The only exception to this was the hash generator, in which both the CUDA and Terracuda versions were of similar length. We attribute this to the fact that C has much simpler ways of dealing with individual bits and bytes (Lua 5.2 does not support bitwise operations), and that when implementing the SHA1 hashing algorithm, the majority of the work is in the algorithm itself, not in the C/CUDA/Terra setup. So even though it was definitely simpler to use Terracuda in this case, the algorithm itself requires a minimum number of steps, which translate directly into lines of code.
Code base comparison also yielded favorable results. Terracuda was consistently less than 1/2 the size of its CUDA counterpart, which emphasizes the concise nature of both Lua and the API we've created. Granted, lines of code is not a perfect benchmark for good/bad code (since it also includes comments/includes/etc.), but it gives us a good impression of relative code sizes. See the results:
References
DeVito, Zachary et al. Terra: A Multi-Stage Language for High-Performance Computing. 2013.
Ierusalimschy, Roberto. Programming in Lua: Third Edition. Lua.org, Jan 2013.
Work done
Equal work was performed by both project members.
Checkpoint
The project is proceeding mostly according to plan. Here's the highlights:
- Because of some troubles with installation/setup/learning overhead, the API is not as close to completion as it should be. That said, as you can see in the Github repo we have made significant progress in creating a high-level CUDA API. We have multiple flavors of a map primitive (which is the basic underpinning of any CUDA program). Soon we'll have support for managing multiple variables/kernels within a CUDA program instead of a single list.
We've benchmarked a basic program and seen some cool performance gains. We ran the following code over an array length 100k
terra do_work(x : int) : int var y : int = 0 for i = 0, 10000 do if i % 3 == 0 or i % 5 == 0 then y = y + 1 end end return x + y endAnd we found speedups of 7.6x over JIT'd Terra, 14.34x over native C, and within 0.95x of hand-rolled CUDA. And the mapping API is really easy to use, it just looks like:
local kernel = cuda.lua_map(do_work) kernel(some_list)And some_list gets modified in-place.
- After a lot of blood and tears, we managed to port the serial and CUDA circle renderers to Lua (so we are ahead of schedule in that respect!). We still need to implement the optimizations from asst2 (e.g. quadtree data structure on the circles) and change it to use more of our newly minted API, but that should come quickly in the next few weeks. For the competition, we'll show off the circle renderer and any other examples we may come up with before then. We'll also have graphs comparing speed and code size using our API.
- At this point, most of the work is just programming and any further API design as our needs develop. We're not facing any serious issues at this point.
Proposal
Summary
We will create a CUDA API for Lua aimed at programmers unfamiliar with GPU-level parallelism.
Background
Lua is a fast, lightweight, and embeddable scripting language found in places like Wikipedia, World of Warcraft, Photoshop Lightroom, and more. Lua's simple syntax and dynamic typing also make it an ideal language for novice programmers. Traditionally, languages like Lua find themselves abstracted miles above low-level parallel frameworks like CUDA, and consequently GPU parallelism was limited to programmers using a systems language like C++. Frameworks like Terra, however, work to close that gap, making low-level programming accessible in a high-level interface. However, these interfaces still require a number of calls to C libraries and intimate knowledge of the CUDA library. For example, the following code runs a simple CUDA kernel in Terra:
terra foo(result : &float)
var t = tid()
result[t] = t
end
local R = terralib.cudacompile({ bar = foo })
terra run_cuda_code(N : int)
var data : &float
C.cudaMalloc([&&opaque](&data),sizeof(float)*N)
var launch = terralib.CUDAParams { 1,1,1, N,1,1, 0, nil }
R.bar(&launch,data)
var results : &float = [&float](C.malloc(sizeof(float)*N))
C.cudaMemcpy(results,data,sizeof(float)*N,2)
return results;
end
results = run_cuda_code(16)Other high-level CUDA bindings like PyCUDA and JCuda suffer the same problem.
The Challenge
The problem is challenging foremost on the level of architecture. Designing an API is never easy, and attempting to expose GPU-level parallelism to a language as high-level as Lua requires a great deal of care to be usable while still being useful. Creating such an API requires significant knowledge of the abstraction layers between Lua, C, and CUDA as well as knowledge of the typical use cases for high-level parallelism.
My partner and I know neither Terra nor LLVM (which Terra compiles to), so creating these high-level bindings requires a great deal of initial investment. The existing interface between Terra and CUDA is sketchy at best, so we will need to implement significant new functionality into Terra in order for the Circle Renderer to function properly.
Resources
For machines, we'll just be using any computers equipped with NVIDIA GPUs (i.e. Will's laptop and the Gates 5k machines). No other special hardware/software will be needed. We'll be building upon the Terra language and also using LuaGL for some of the demos.
Goals
The project has three main areas: writing the API, creating programs using the API, and benchmarking the code against other languages/compilers.
We plan to achieve:
- Writing the API
- Allow arbitrary Lua code to be executed in the GPU over a table.
- Optimize threads/warp usage to the input data.
- Abstract the API such that the user needs no C libraries and as little Terra as possible.
- Creating programs
- Make a simple saxpy
- Write matrix operations like transpose or pseudoinverse/SVD
- Port the Assignment 2 Circle Renderer over to vanilla Lua (using LuaGL)
- Benchmarking
- For each program, benchmark it against equivalent implementations in: vanilla Lua, Terra without CUDA, and C.
We hope to achieve:
- Achieve better performance than vanilla C.
- Implement shared memory in Terra.
- Implement linking against libraries like cublas.
Platform
CUDA makes sense as we've already learned it in class, and Lua makes sense as Terra already laid the foundation for abstracting systems-level code.
Schedule
Original schedule
- Friday, April 11: finish map primitives (ie any Lua code and map over a Lua table in CUDA). Write saxpy and corresponding benchmarks.
- Friday, April 18: complete Terracuda API. Write matrix code and benchmarks.
- Friday, April 25: Port over Circle Renderer and benchmarks. Gather all requisite data and perform preliminary analysis.
- Friday, May 2: Optimize/refactor API based on code written and data found. Search for possible performance gains in the abstraction layer. Attempt to implement library linking.
- Friday, May 9: create writeup based on finalized API. Add any remaining features, time permitting (.g. shared memory).
New schedule
- Wednesday, April 23: implement generic kernel/variable and reduce primitives (Will).
- Sunday, April 27: finish implementing optimizations in circle renderer (Patrick).
- Wednesday, April 30: finish refactors to API. Add shared/constant memory if possible (Will).
- Sunday, May 3: finish benchmarking all programs. Gather and graph data. (Patrick).
- Wednesday, May 7: complete write-up (Will and Patrick). Time permitting, make more demos.