$$
% Typography and symbols
\newcommand{\msf}[1]{\mathsf{#1}}
\newcommand{\ctx}{\Gamma}
\newcommand{\qamp}{&\quad}
\newcommand{\qqamp}{&&\quad}
\newcommand{\Coloneqq}{::=}
\newcommand{\proves}{\vdash}
\newcommand{\star}[1]{#1^{*}}
\newcommand{\eps}{\varepsilon}
\newcommand{\nul}{\varnothing}
\newcommand{\brc}[1]{\{{#1}\}}
\newcommand{\binopm}[2]{#1~\bar{\oplus}~#2}
\newcommand{\mag}[1]{|{#1}|}
\newcommand{\aequiv}{\equiv_\alpha}
\newcommand{\semi}[2]{{#1};~{#2}}
% Untyped lambda calculus
\newcommand{\fun}[2]{\lambda ~ {#1} ~ . ~ {#2}}
\newcommand{\app}[2]{#1 ~ #2}
\newcommand{\fix}[3]{\msf{fix}~({#1} : {#2}) ~ . ~ #3 }
\newcommand{\truet}{\msf{true}}
\newcommand{\falset}{\msf{false}}
\newcommand{\define}[2]{{#1} \triangleq {#2}}
% Typed lambda calculus - expressions
\newcommand{\funt}[3]{\lambda ~ \left(#1 : #2\right) ~ . ~ #3}
\newcommand{\lett}[4]{\msf{let} ~ \hasType{#1}{#2} = #3 ~ \msf{in} ~ #4}
\newcommand{\letrec}[4]{\msf{letrec} ~ \hasType{#1}{#2} = #3 ~ \msf{in} ~ #4}a
\newcommand{\ift}[3]{\msf{if} ~ {#1} ~ \msf{then} ~ {#2} ~ \msf{else} ~ {#3}}
\newcommand{\rec}[5]{\msf{rec}(#1; ~ #2.#3.#4)(#5)}
\newcommand{\case}[5]{\msf{case} ~ {#1} ~ \{ L(#2) \to #3 \mid R(#4) \to #5 \}}
\newcommand{\pair}[2]{\left({#1},~{#2}\right)}
\newcommand{\proj}[2]{#1 . #2}
\newcommand{\inj}[3]{\msf{inj} ~ #1 = #2 ~ \msf{as} ~ #3}
\newcommand{\letv}[3]{\msf{let} ~ {#1} = {#2} ~ \msf{in} ~ {#3}}
\newcommand{\fold}[2]{\msf{fold}~{#1}~\msf{as}~{#2}}
\newcommand{\unfold}[1]{\msf{unfold}~{#1}}
\newcommand{\poly}[2]{\Lambda~{#1}~.~ #2}
\newcommand{\polyapp}[2]{{#1}~\left[{#2}\right]}
\newcommand{\export}[3]{\msf{export}~ #1 ~\msf{without}~{#2}~\msf{as}~ #3}
\newcommand{\import}[4]{\msf{import} ~ ({#1}, {#2}) = {#3} ~ \msf{in} ~ #4}
% Typed lambda calculus - types
\newcommand{\tnum}{\msf{num}}
\newcommand{\tstr}{\msf{string}}
\newcommand{\tint}{\msf{int}}
\newcommand{\tbool}{\msf{bool}}
\newcommand{\tfun}[2]{#1 \rightarrow #2}
\newcommand{\tprod}[2]{#1 \times #2}
\newcommand{\tsum}[2]{#1 + #2}
\newcommand{\trec}[2]{\mu~{#1}~.~{#2}}
\newcommand{\tvoid}{\msf{void}}
\newcommand{\tunit}{\msf{unit}}
\newcommand{\tpoly}[2]{\forall~{#1}~.~{#2}}
\newcommand{\tmod}[2]{\exists ~ {#1} ~ . ~ #2}
% WebAssembly
\newcommand{\wconst}[1]{\msf{i32.const}~{#1}}
\newcommand{\wbinop}[1]{\msf{i32}.{#1}}
\newcommand{\wgetlocal}[1]{\msf{get\_local}~{#1}}
\newcommand{\wsetlocal}[1]{\msf{set\_local}~{#1}}
\newcommand{\wgetglobal}[1]{\msf{get\_global}~{#1}}
\newcommand{\wsetglobal}[1]{\msf{set\_global}~{#1}}
\newcommand{\wload}{\msf{i32.load}}
\newcommand{\wstore}{\msf{i32.store}}
\newcommand{\wsize}{\msf{memory.size}}
\newcommand{\wgrow}{\msf{memory.grow}}
\newcommand{\wunreachable}{\msf{unreachable}}
\newcommand{\wblock}[1]{\msf{block}~{#1}}
\newcommand{\wloop}[1]{\msf{loop}~{#1}}
\newcommand{\wbr}[1]{\msf{br}~{#1}}
\newcommand{\wbrif}[1]{\msf{br\_if}~{#1}}
\newcommand{\wreturn}{\msf{return}}
\newcommand{\wcall}[1]{\msf{call}~{#1}}
\newcommand{\wlabel}[2]{\msf{label}~\{#1\}~{#2}}
\newcommand{\wframe}[2]{\msf{frame}~({#1}, {#2})}
\newcommand{\wtrapping}{\msf{trapping}}
\newcommand{\wbreaking}[1]{\msf{breaking}~{#1}}
\newcommand{\wreturning}[1]{\msf{returning}~{#1}}
\newcommand{\wconfig}[5]{\{\msf{module}{:}~{#1};~\msf{mem}{:}~{#2};~\msf{locals}{:}~{#3};~\msf{stack}{:}~{#4};~\msf{instrs}{:}~{#5}\}}
\newcommand{\wfunc}[4]{\{\msf{params}{:}~{#1};~\msf{locals}{:}~{#2};~\msf{return}~{#3};~\msf{body}{:}~{#4}\}}
\newcommand{\wmodule}[1]{\{\msf{funcs}{:}~{#1}\}}
\newcommand{\wcg}{\msf{globals}}
\newcommand{\wcf}{\msf{funcs}}
\newcommand{\wci}{\msf{instrs}}
\newcommand{\wcs}{\msf{stack}}
\newcommand{\wcl}{\msf{locals}}
\newcommand{\wclab}{\msf{labels}}
\newcommand{\wcm}{\msf{mem}}
\newcommand{\wcmod}{\msf{module}}
\newcommand{\wsteps}[2]{\steps{\brc{#1}}{\brc{#2}}}
\newcommand{\with}{\underline{\msf{with}}}
\newcommand{\wvalid}[2]{{#1} \vdash {#2}~\msf{valid}}
\newcommand{\wif}[2]{\msf{if}~{#1}~{\msf{else}}~{#2}}
\newcommand{\wfor}[4]{\msf{for}~(\msf{init}~{#1})~(\msf{cond}~{#2})~(\msf{post}~{#3})~{#4}}
% assign4.3 custom
\newcommand{\wtry}[2]{\msf{try}~{#1}~\msf{catch}~{#2}}
\newcommand{\wraise}{\msf{raise}}
\newcommand{\wraising}[1]{\msf{raising}~{#1}}
\newcommand{\wconst}[1]{\msf{i32.const}~{#1}}
\newcommand{\wbinop}[1]{\msf{i32}.{#1}}
\newcommand{\wgetlocal}[1]{\msf{get\_local}~{#1}}
\newcommand{\wsetlocal}[1]{\msf{set\_local}~{#1}}
\newcommand{\wgetglobal}[1]{\msf{get\_global}~{#1}}
\newcommand{\wsetglobal}[1]{\msf{set\_global}~{#1}}
\newcommand{\wload}{\msf{i32.load}}
\newcommand{\wstore}{\msf{i32.store}}
\newcommand{\wsize}{\msf{memory.size}}
\newcommand{\wgrow}{\msf{memory.grow}}
\newcommand{\wunreachable}{\msf{unreachable}}
\newcommand{\wblock}[1]{\msf{block}~{#1}}
\newcommand{\wloop}[1]{\msf{loop}~{#1}}
\newcommand{\wbr}[1]{\msf{br}~{#1}}
\newcommand{\wbrif}[1]{\msf{br\_if}~{#1}}
\newcommand{\wreturn}{\msf{return}}
\newcommand{\wcall}[1]{\msf{call}~{#1}}
\newcommand{\wlabel}[2]{\msf{label}~\{#1\}~{#2}}
\newcommand{\wframe}[2]{\msf{frame}~({#1}, {#2})}
\newcommand{\wtrapping}{\msf{trapping}}
\newcommand{\wbreaking}[1]{\msf{breaking}~{#1}}
\newcommand{\wreturning}[1]{\msf{returning}~{#1}}
\newcommand{\wconfig}[5]{\{\msf{module}{:}~{#1};~\msf{mem}{:}~{#2};~\msf{locals}{:}~{#3};~\msf{stack}{:}~{#4};~\msf{instrs}{:}~{#5}\}}
\newcommand{\wfunc}[4]{\{\msf{params}{:}~{#1};~\msf{locals}{:}~{#2};~\msf{return}~{#3};~\msf{body}{:}~{#4}\}}
\newcommand{\wmodule}[1]{\{\msf{funcs}{:}~{#1}\}}
\newcommand{\wcg}{\msf{globals}}
\newcommand{\wcf}{\msf{funcs}}
\newcommand{\wci}{\msf{instrs}}
\newcommand{\wcs}{\msf{stack}}
\newcommand{\wcl}{\msf{locals}}
\newcommand{\wcm}{\msf{mem}}
\newcommand{\wcmod}{\msf{module}}
\newcommand{\wsteps}[2]{\steps{\brc{#1}}{\brc{#2}}}
\newcommand{\with}{\underline{\msf{with}}}
\newcommand{\wvalid}[2]{{#1} \vdash {#2}~\msf{valid}}
% assign4.3 custom
\newcommand{\wtry}[2]{\msf{try}~{#1}~\msf{catch}~{#2}}
\newcommand{\wraise}{\msf{raise}}
\newcommand{\wraising}[1]{\msf{raising}~{#1}}
\newcommand{\wif}[2]{\msf{if}~{#1}~{\msf{else}}~{#2}}
\newcommand{\wfor}[4]{\msf{for}~(\msf{init}~{#1})~(\msf{cond}~{#2})~(\msf{post}~{#3})~{#4}}
\newcommand{\windirect}[1]{\msf{call\_indirect}~{#1}}
% session types
\newcommand{\ssend}[2]{\msf{send}~{#1};~{#2}}
\newcommand{\srecv}[2]{\msf{recv}~{#1};~{#2}}
\newcommand{\soffer}[4]{\msf{offer}~\{{#1}\colon({#2})\mid{#3}\colon({#4})\}}
\newcommand{\schoose}[4]{\msf{choose}~\{{#1}\colon({#2})\mid{#3}\colon({#4})\}}
\newcommand{\srec}[1]{\msf{label};~{#1}}
\newcommand{\sgoto}[1]{\msf{goto}~{#1}}
\newcommand{\dual}[1]{\overline{#1}}
% Inference rules
\newcommand{\inferrule}[3][]{\cfrac{#2}{#3}\;{#1}}
\newcommand{\ir}[3]{\inferrule[\text{(#1)}]{#2}{#3}}
\newcommand{\s}{\hspace{1em}}
\newcommand{\nl}{\\[2em]}
\newcommand{\evalto}{\boldsymbol{\overset{*}{\mapsto}}}
\newcommand{\steps}[2]{#1 \boldsymbol{\mapsto} #2}
\newcommand{\evals}[2]{#1 \evalto #2}
\newcommand{\subst}[3]{[#1 \rightarrow #2] ~ #3}
\newcommand{\dynJ}[2]{#1 \proves #2}
\newcommand{\dynJC}[1]{\dynJ{\ctx}{#1}}
\newcommand{\typeJ}[3]{#1 \proves \hasType{#2}{#3}}
\newcommand{\typeJC}[2]{\typeJ{\ctx}{#1}{#2}}
\newcommand{\hasType}[2]{#1 : #2}
\newcommand{\val}[1]{#1~\msf{val}}
\newcommand{\num}[1]{\msf{Int}(#1)}
\newcommand{\err}[1]{#1~\msf{err}}
\newcommand{\trans}[2]{#1 \leadsto #2}
\newcommand{\size}[1]{\left|#1\right|}
$$
The Future of Notebooks: Lessons from JupyterCon
Will Crichton
—
August 24, 2018
At JupyterCon, I learned three things: reactive notebooks are the future, Jupyter is the new Bash, and data science is a gateway drug.
Over the last two days at JupyterCon, I saw a lot of exciting ideas about the future of Jupyter notebooks. I’ve already written about my own ideas—Jupyter for debugging, Jupyter for prototyping interactions—but in this note, I want to highlight the major trends I saw in the JupyterCon presentations.
1. Reactive notebooks
In the talk “I don’t like notebooks”, Joel Grus’ number one (or at least first) complaint about Jupyter is that “notebooks have tons and tons of hidden state that’s easy to screw up and difficult to reason about.” Although Jupyter displays cells in a linear order, they can be executed, edited, and re-executed in any order.
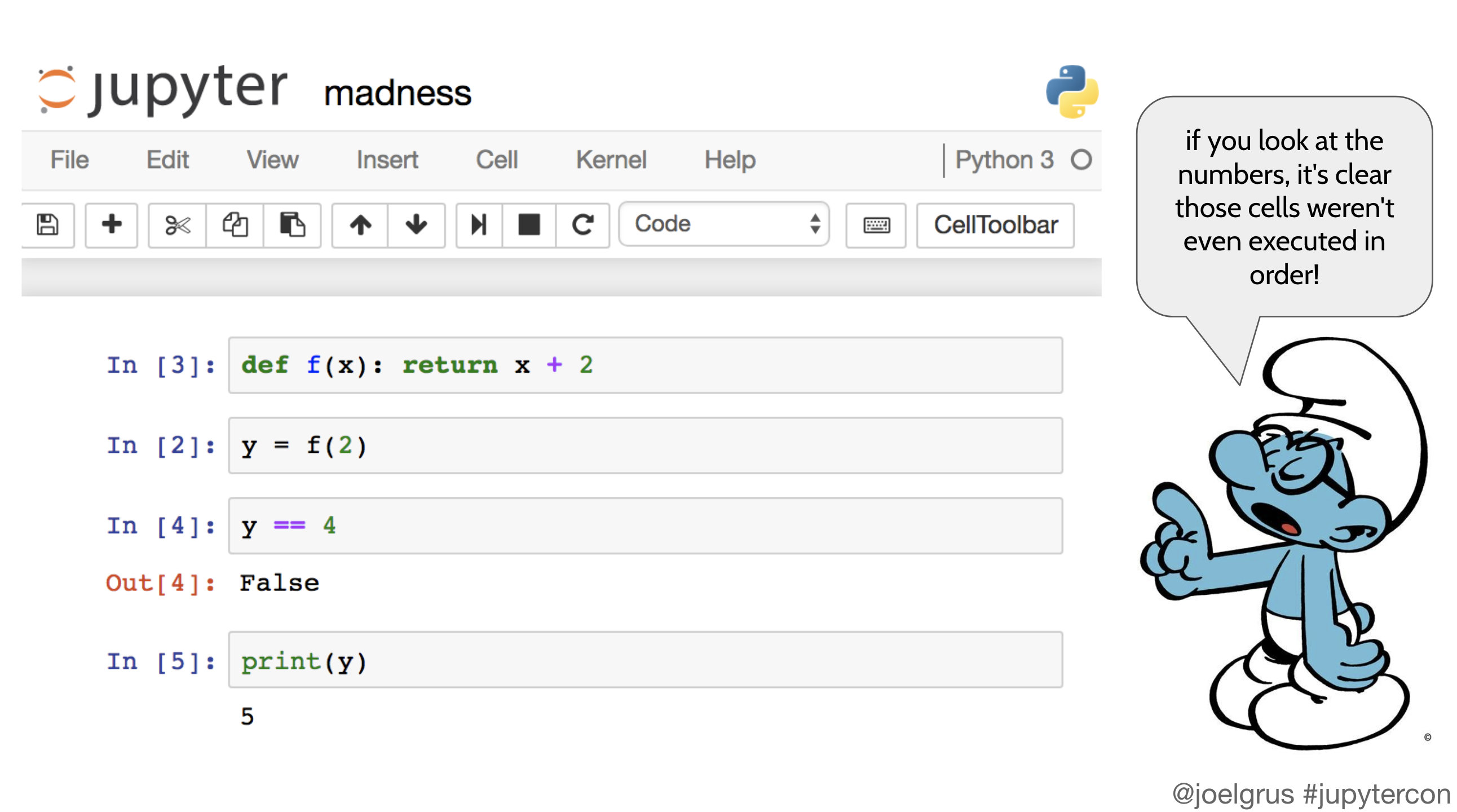
Two subsequent talks, “Supporting reproducibility in Jupyter through dataflow notebooks” and “Explorations in reproducible analysis with Nodebook”, explored new systems that address this problem by turning Jupyter into a reactive programming environment. In reactive programming, the runtime tracks dependencies between cells and knows to re-run a cell when its dependencies change.
The two systems, dfkernel and Nodebook, have different mechanisms for tracking updates. Both only track variables in the global scope. Dfkernel conservatively invalidates all global variables used in a particular cell. Nodebook computes the hash of the serialization of every global variable on every cell execution, and compares the hashes to the previous hashes to determine invalidation. Nodebook additionally enforces the constraint that cells can only have data dependencies on prior cells.
While neither seems like a fully optimal solution, it does seem like reactive notebooks are growing in popularity. Observable’s Javascript notebooks also adopt this idea.
2. Jupyter is the new Bash
While Jupyter notebooks have traditionally been a humans-only entrypoint into a program, researchers and companies alike are increasingly using notebooks for automation. In “Scheduled notebooks: A means for manageable and traceable code execution”, a Netflix engineer described how they have replaced Bash scripts with Jupyter notebooks for ETL pipelines and cron jobs.
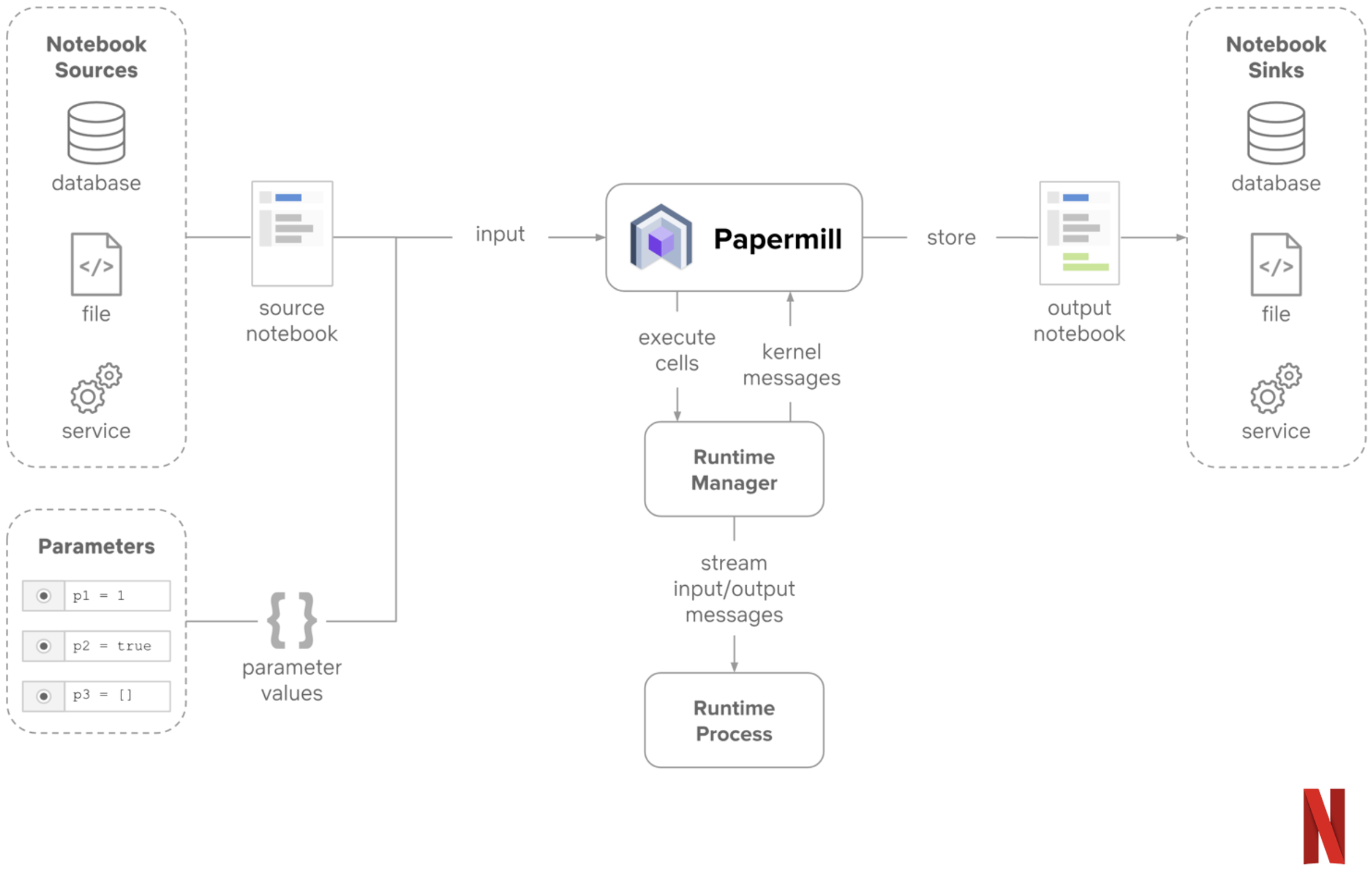
The basic idea is that you write a parameterized Jupyter notebook, essentially a notebook with parameters that get pasted into a new block at the top of the notebook. A system called Papermill metaprograms a bespoke notebook with provided parameters pasted in, and then executes the notebook with zero user interaction required. For Netflix, the benefit of this approach is to simplify the development and debugging of these scripts. If a particular job breaks, it’s trivial to pop open the offending notebook in the normal Jupyter environment, and it has all the data built in that it needs to execute until hitting the error.
A more experimental approach to this is Script of Scripts, a Jupyter kernel that allows users to bridge between multiple programming languages (e.g. Python, Bash, and R) in a single Jupyter notebook.
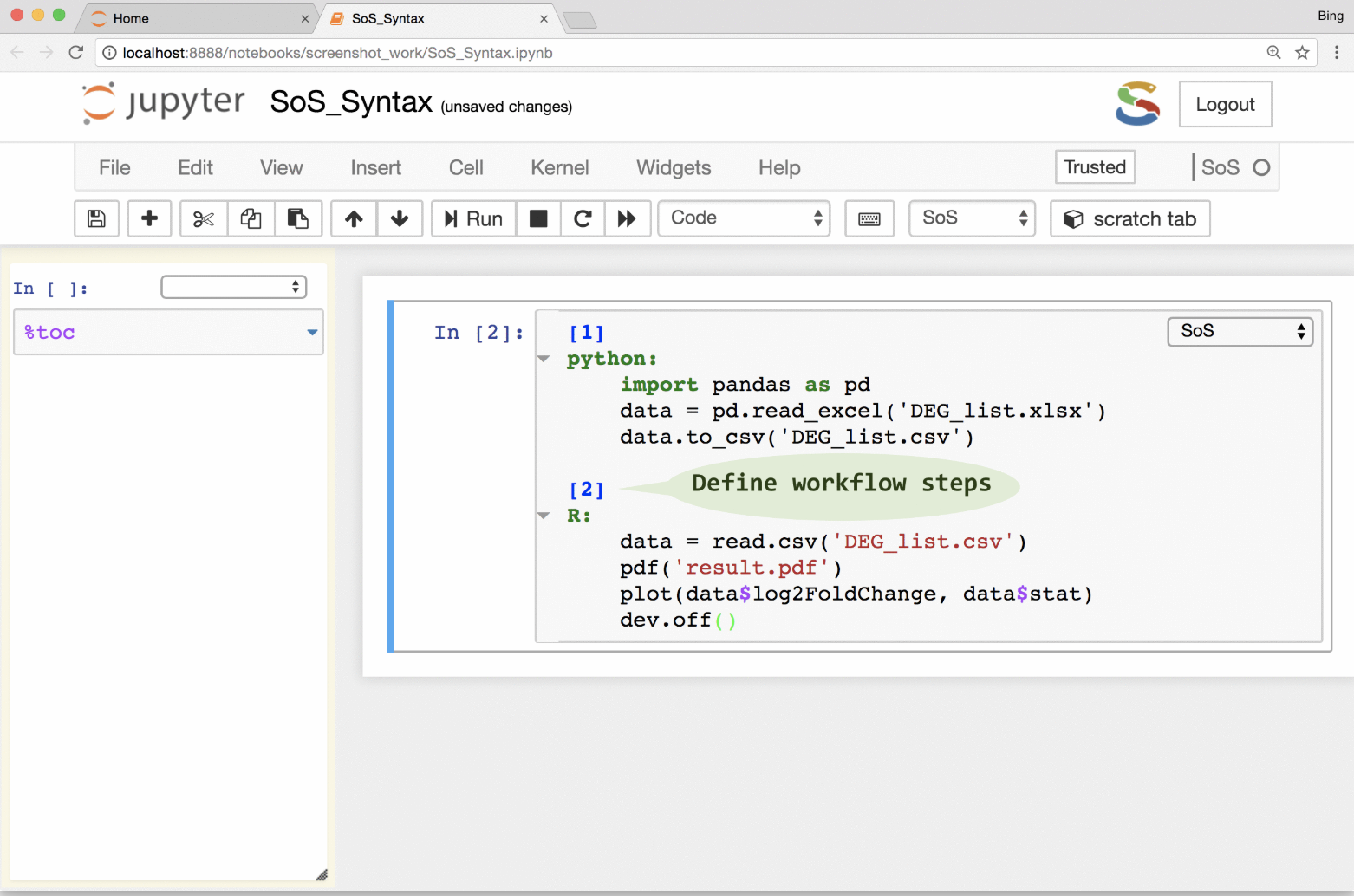
The SoS system integrates into traditional cluster schedulers like slurm, enabling their group at University of Texas to write Jupyter notebooks instead of Bash scripts to create bioinformatics pipelines.
3. Data science as a gateway drug in education
On the education side of things, Jupyter is quickly gaining adoption in universities around America, particularly for data science courses. Conversely, data science is increasingly becoming students’ first exposure to programming and computer science, not just a supplement to a CS curriculum. Most notable is UC Berkeley’s Data 8 program, which is projected to reach 50% of the university’s undergraduates within the next few years.
The neat part about Data 8 is that it starts with a core class, but branches into many sister classes that incorporate data science principles to investigate domains like medicine, geography, and sports. Their pedagogy is to develop a series of independent modules on topics like hypothesis testing, text processing, etc. such that courses can incorporate modules as necessary for their domain.
I think this is a reasonable reaction to the utterly contrived assignments in many first-year programming courses—it’s way more motivating to gain insight in domains I actually care about as opposed to writing a routine to sort a list or search a tree.
Other cool things I saw but haven’t covered: JupyterLab (web-based window manager and IDE), JupyterHub (multi-user server for Jupyter), Binder (hosted notebooks), nbinteract (convert interactive notebooks into web pages), Quilt (data versioning), and Xeus (C++ kernel in Jupyter).