Type-Driven API Design in Rust
This book is for people who are writing APIs in Rust. In particular, APIs that involve complex abstractions: variadics, state machines, extensible architectures, and so on.
The central theme is how to enforce API design by replacing dynamically-typed abstractions with statically-typed ones.
To understand this book's content, you should be familiar with Rust's core features: ownership, generics, traits, closures — anything covered in TRPL.
A prototypical example: enums over strings
A basic example of this theme is using enums to represent a finite set of options, rather than a string. Imagine trying to convert a description of a primary color to an RGB tuple. This API design is error-prone:
#![allow(unused)] fn main() { fn color_to_rgb_bad(color: &str) -> Option<(u8, u8, u8)> { match color { "Red" => Some((255, 0, 0)), "Yellow" => Some((255, 255, 0)), "Blue" => Some((0, 0, 255)), _ => None } } }
While this design avoids errors:
#![allow(unused)] fn main() { enum PrimaryColor { Red, Yellow, Blue } fn color_to_rgb_good(color: PrimaryColor) -> (u8, u8, u8) { match color { PrimaryColor::Red => (255, 0, 0), PrimaryColor::Yellow => (255, 255, 0), PrimaryColor::Blue => (0, 0, 255) } } }
Specifically, errors could happen either for a API client or the API author:
- For a API client, the
colorparameter in the first example is an dynamically-typed (or "stringly-typed") abstraction because the compiler cannot verify whether a call tocolor_to_rgb_badwill always contain one of the three strings. By contrast, incolor_to_rgb_good, the input is guaranteed to be one of the enum values. Consequently, theOptionis removed from the type signature because the method can no longer fail. - For the API author, the compiler does not enforce that the implementation of
color_to_rgb_badmatches on the strings intended by the author. If they wrote"Rod"instead of"Red", the error would only arise in a unit test or client bug report. By contrast, the compiler enforces that each enum variants must be one of the three enum values.
What if you need to take
&stras input, e.g. from a user at the command line? Then don't try to accomplish two things in one function. Define a separate function:fn parse(input: &str) -> Option<PrimaryColor>Check out "Parse, don't validate" for a deeper philosophy on this style of design.
Book structure
The remainder of the book is structured much like the example above.
- I'll describe a pattern that arises in API design, like having multiple options as a function input.
- I'll show how a general mechanism, like enums, can encode aspects of the design into types.
- I'll go through what errors can happen in each flavor of API.
You can consume this book à la carte, reading individual chapters as they're useful to you. But each chapter does (somewhat) build on the previous ones, so you may enjoy a start-to-finish read as well.
The Main Idea
An API is a computational representation of real-world concepts. Representations are mappings between elements of a represented world (e.g. a primary color) and a representing world (e.g. an enum in a programming language). A concept can have many representations — for instance, a number can be expressed many ways:
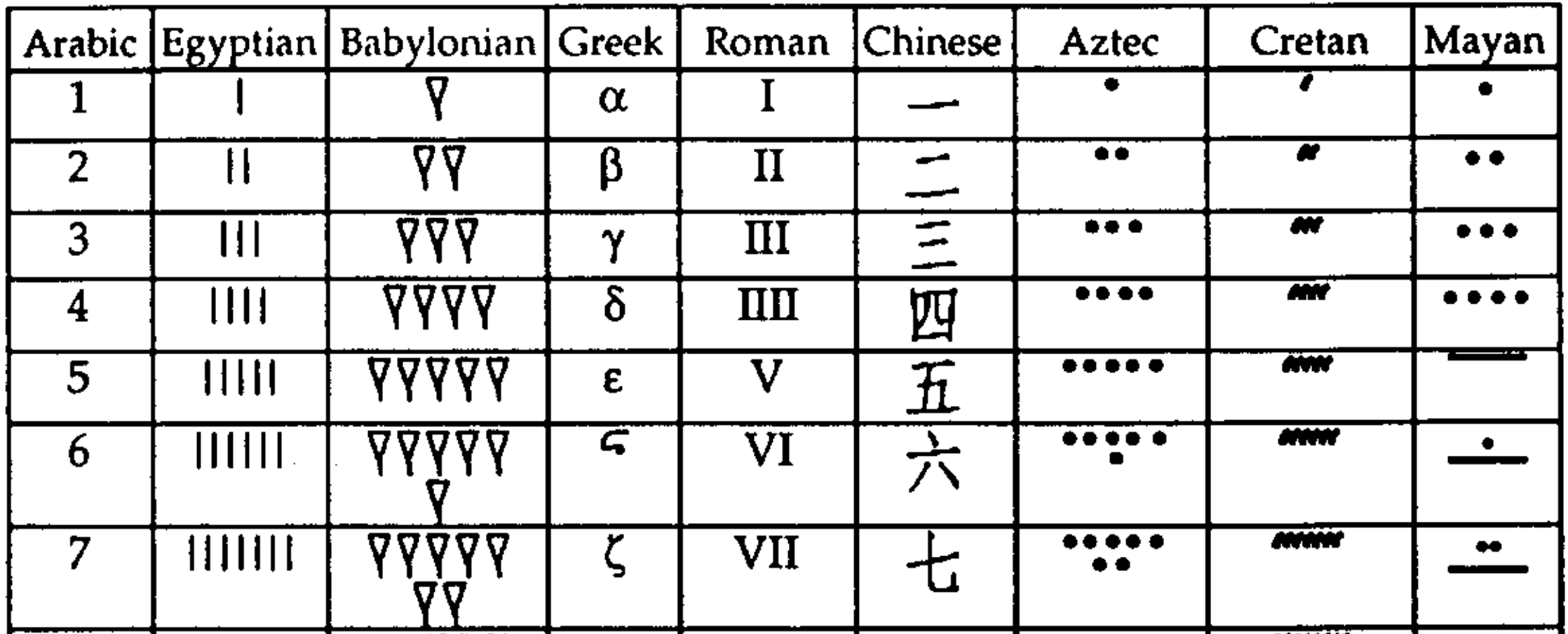
Zhang and Norman, A Representational Analysis of Numeration Systems. 1996
As an API designer, your goal is to pick a representation that best supports its intended tasks. For example, a number representation should make it easy to add and multiply two numbers.
A skilled API designer can design representations systematically, understanding the structure of representations that makes tasks easier or harder. For example, numbers can be categorized along a few dimensions:
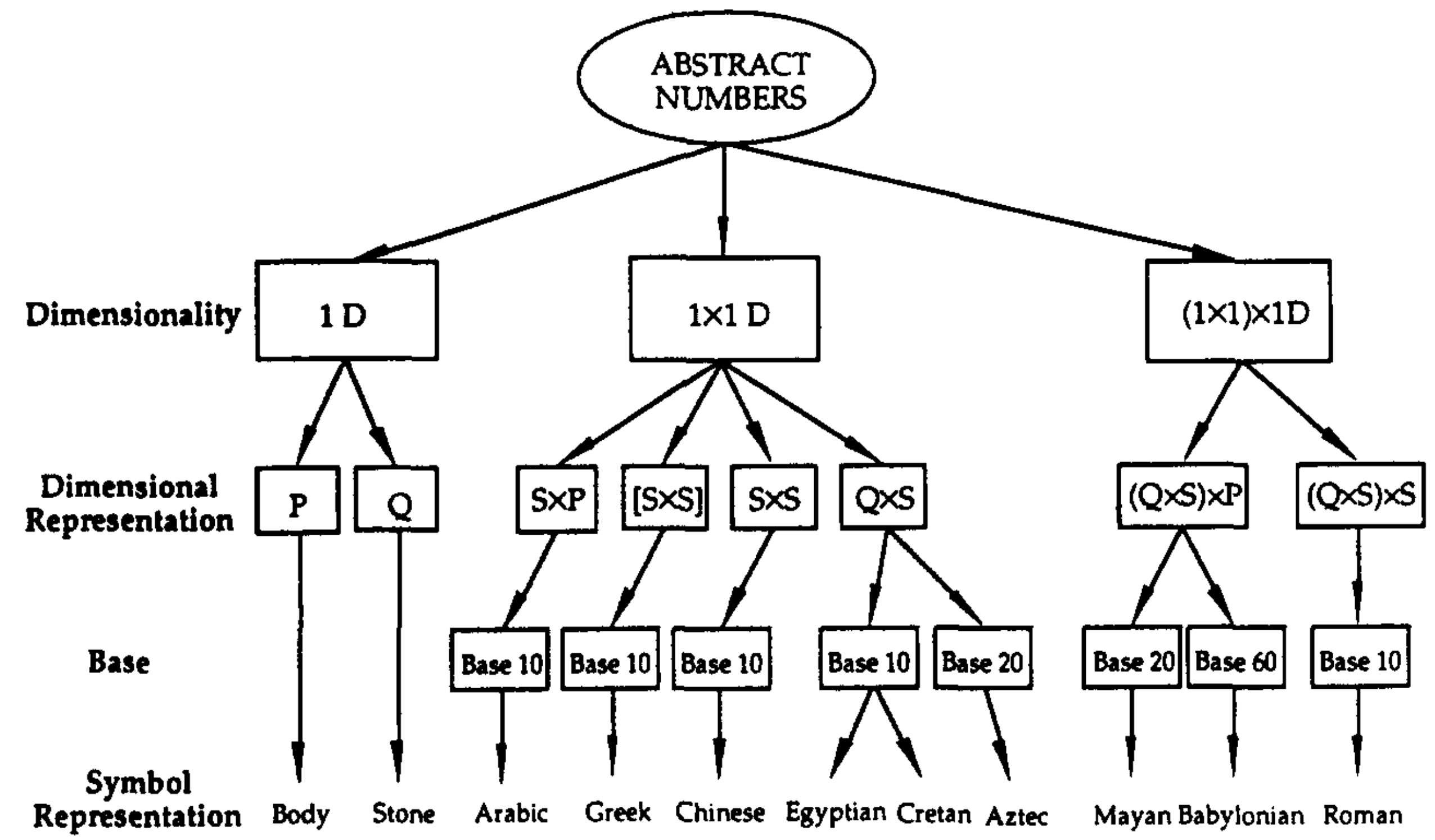
Using this taxonomy, we can understand that all 1D systems (like tally marks) make addition easier, because addition reduces to concatenating strings (e.g. II + I = III). However, 1x1D systems (like Arabic numerals) make multiplication easier — see the paper for why.
If you're interested in learning more about representation theory in cognitive psychology, I strongly recommend Things That Make Us Smart by Don Norman.
In this book, my goal is to show you how representational principles can be used to improve API design. That is, when you map the real world to an API, how can you help API clients be more productive and avoid mistakes?
Principles of representation: cardinality mismatch
Consider the example from the last chapter. We want to define a data type that represents the three primary colors. We could do this as either a string or an enum:
fn color_to_rgb_bad(color: &str) // ...
enum PrimaryColor { Red, Yellow, Blue }
fn color_to_rgb_good(color: PrimaryColor) // ..
Here, an enum is preferable to a string because there is a one-to-one map from elements of the representation to elements of the concept. By contrast, the type &str includes many more strings than primary colors. Because &str is not one-to-one, the color_to_rgb_bad function must handle the additional case of elements in the representation that don't exist in the concept.
Previously, we justified the enum design in terms of potential errors avoided. But the point is that these errors are symptoms of a deeper issue: cardinality mismatch. And when we explicitly articulate this principle, then we can more easily apply it to new situations.
For example, cardinality mismatch can happen in multiple ways: consider a situation where an API's representation might contain fewer elements than those in the concept. Consider a variant of Rust's fs::read_to_string function which returns a bool instead of Result<String, io::Error>.
#![allow(unused)] fn main() { use std::{io::Read, path::PathBuf, fs::File}; fn read_to_string(path: String, buffer: &mut String) -> bool { let mut file = if let Ok(f) = File::open(PathBuf::from(path)) { f } else { return false; }; if !file.read_to_string(buffer).is_ok() { return false; } return true; } }
In this API design, the bool represents the concept of success or failure. However, I/O can fail for a number reason, e.g. if the file is not found or the user does not have read permission. The Result representation has a one-to-one mapping because io::Error has a separate value for each I/O error, while the false value must represent every I/O error. The consequence of the bool design is that the client cannot distinguish between failure cases given a return value of false.
The main idea: consistency between related elements
This main idea of this book is a principle of representation: consistency between related elements. In a system with many parts, it's often important that certain pieces be in sync with each other. For example:
- In an event listener, the event name (e.g.
"click") must be consistent with the event parameters (e.g.mousex). - In a state machine, the machine's state (e.g.
FileOpen) must be consistent with the set of actions permissible on the machine (e.g..close()). - In a function with variadic arguments, the order of arguments (e.g.
route("/:user/:message")) must be consistent with the order of usage (e.g.|u: User, m: Message|).
Another way of interpreting this principle is "when multiple components must agree on aspects of an entity", which is known as connascence.
Enforcing consistency is often easier in a closed system, where every piece is defined and no further ones can be added. For example, consider an (inefficient) event system with a fixed set of events:
#![allow(unused)] fn main() { enum Event { Click { mousex: usize, mousey: usize }, KeyPress { keycode: usize } } struct EventSystem { listeners: Vec<Box<dyn FnMut(Event) -> ()>> } impl EventSystem { fn add_listener(&mut self, f: impl FnMut(Event) -> () + 'static) { self.listeners.push(Box::new(f)); } } fn example() { let mut events = EventSystem { listeners: Vec::new() }; events.add_listener(|e| { if let Event::Click { mousex, mousey } = e { println!("Clicked: x={}, y={}", mousex, mousey); } }); } }
The nature of Rust's enum enforces that if a Click event occurred, then (and only then) will the listener be able to access the mousex field. However, what if an API client wanted to add another event to the system? They cannot reach into the API and add another enum variant.
Therein lies the core technical challenge: how can an API enforce consistency between related elements in an open system? Over the next few chapters, you'll learn how careful use of Rust's type system can achieve both of these goals.
Access control
A common pattern in system design is that X can only happen if Y is true.
- A user can only access their account settings if logged in.
- A piece of data can only be accessed if its mutex is locked.
- A file can only be read if a user has read permissions.
These properties are all instances of access control, where the ability to execute an action is predicated on access privileges.
In terms of our representational principle, the two conceptual elements are the action (eg opening a webpage, reading data) and the access (logged in, locked a mutex). We will look at how to design APIs to ensure consistency between the action and the access.
Witnesses
Let's say we're designing a website with a panel that only admins can access. A naive approach relies on enforcing access control by convention:
/// IMPORTANT: Only call this function when logged in as admin!
fn render_admin_panel() -> Html {
// ...
}
fn admin_panel_route_ok() -> Html {
// We could remember to check...
if current_user().is_admin() {
render_admin_panel();
} else {
render_404();
}
}
fn admin_panel_route_whoops() -> Html {
// Or we could just forget!
render_admin_panel();
}
Here's an alternative API design that turns the convention into a requirement:
mod admin {
// When Admin is hidden in a module,
// it can only be constructed by exported functions
pub struct Admin { /* .. */ }
impl User {
// Only returns Some(Admin) if user is an admin
pub fn try_admin(&self) -> Option<Admin> { /* ... */ }
}
}
// We add Admin as a parameter to the render function
fn render_admin_panel(_admin: admin::Admin) -> Html {
// ...
}
fn admin_panel_route_ok() -> Html {
if let Some(admin) = current_user().try_admin() {
render_admin_panel(admin);
} else {
render_404();
}
}
fn admin_panel_route_whoops() -> Html {
// TYPE ERROR: current_user() is not an admin!
render_admin_panel(current_user());
// TYPE ERROR: Admin has private fields and cannot be constructed
render_admin_panel(admin::Admin { .. });
}
Here, the Admin struct is an example of a witness: an object that proves (or "witnesses") a particular property, e.g. that a user is an admin. (The term comes from proof theory.) The witness pattern relies on two ideas:
-
Witnesses prove properties by construction. The only way to create a value of type
Adminshould be viatry_admin. If this is true, then having access to a value of typeAdminis a proof that a user is an admin. "By construction" means the act of creating a value is equivalent to creating a proof of what that value represents (see: Curry-Howard correspondence). -
Code that relies on properties takes witnesses as input. If an admin panel should only be rendered by an admin, then
render_admin_panelshould require that the function caller prove it has admin access. Even if the actualadminvalue is never used, because it is a required input, the function cannot be called without proof of access.
With these two ideas, the witness pattern can statically enforce access control. Witnesses encode access capabilities, and actions require witnesses before being executed. For a real-world example, check out Request Guards in the Rocket framework (see also Sergio's lecture notes).
Guards
Recall that witnesses are proofs of properties, like being a website admin. In the witness pattern, the actual value (e.g. admin: Admin) may not actually be used at runtime — its presence is purely for statically enforcing access control. When using witnesses, the API designer must carefully ensure that every time a piece of code makes an assumption (e.g. user is an admin), that the code has access to a corresponding witness.
An alternative approach is to associate a witness with its runtime capabilities. To dig into that statement, we'll use the running example of a Mutex<T> that protects a value of type T given a SystemMutex (e.g. pthread_mutex). Recall that a mutex should satisfy the following design goals:
- Access control: Only one thread can access
Tat any given time by callingSystemMutex::lock. - Cleanup: Once a thread has finished accessing
T, it should callSystemMutex::unlock.
Here's a hypothetical Mutex<T> API:
struct Mutex<T> {
t: UnsafeCell<T>,
system_mutex: SystemMutex
}
impl<T> Mutex<T> {
pub fn new(t: T) -> Self { /* .. */ }
pub fn lock(&self) -> &mut T {
self.system_mutex.lock();
unsafe { &mut *self.t.get() }
}
pub fn unlock(&self) {
self.system_mutex.unlock();
}
}
fn main() {
let mtx = Mutex::new(1);
let n = mtx.lock();
mtx.unlock();
let n2 = mtx.lock();
// two mutable pointers to same data! very bad!
*n = 1;
*n2 = 2;
}
This API nominally enforces access control via encapsulation: the only way to access T is by calling lock, which ensures that SystemMutex::lock is called. However, the issue is that there is no mechanism which relates the lifetime of &mut T to the lifetime of the lock on the system mutex. So an API client could forget to call Mutex::unlock which violates the cleanup design goal. Or worse, an API client could call Mutex::unlock too early which would allow other threads to access T simultaneously, violating the access control design goal.
Witness approach
How could we try to solve this problem with a witness? One possible approach is to return a witness to a mutex being locked, and use that witness to mediate access and cleanup.
struct MutexIsLocked;
struct Mutex<T> { /* .. */ }
impl<T> Mutex<T> {
fn lock(&self) -> MutexIsLocked {
self.system_mutex.lock();
}
fn unlock(&self, _witness: MutexIsLocked) {
self.system_mutex.unlock();
}
fn get(&self, _witness: &MutexIsLocked) -> &mut T {
unsafe { &mut *self.t.get() }
}
}
fn main() {
let mtx = Mutex::new(1);
let witness = mtx.lock();
let n = mtx.get(&witness);
mtx.unlock(witness);
let witness2 = mtx.lock();
let n2 = mtx.get(&witness2);
*n = 1;
*n2 = 2;
}
This interface is better than the previous one because:
unlockcannot be called at any time, it can only be called afterlockbecause the witness ensures that the mutex is locked.unlockcannot be called multiple times, becauseunlocktakes ownership of the witness.Mutex::getcannot be called afterMutex::unlockbecauseunlocktakes ownership of the witness.
However, this interface still does not satisfy our design goals of access control and cleanup.
- As shown in
main, the lifetime of the&mut Tcan be longer than the lifetime of the witness. So access control is not enforced because dangling pointers toTare held afterunlock. - Nothing relates the
MutexIsLockedwitness to the mutex it came from. You could create two unrelated mutexes, and pass the witness from one into the other.
Again, our main idea returns: consistency between related elements. Our witness-based API does not ensure that access to the mutex's data is consistent with access to the witness of the locked mutex.
Guard approach
Instead of a MutexIsLocked witness, we will use a guard: a data structure that both proves a property (a mutex is locked) and mediates access to data (the mutex's T). The idea is that calling Mutex::lock will return a MutexGuard which manages the system mutex in its constructor and destructor, and it provides access to the inner T.
struct MutexGuard<'a, T> {
lock: &'a Mutex<T>
}
impl<'a, T> MutexGuard<'a, T> {
fn new(lock: &'a Mutex<T>) -> Self {
lock.system_mutex.lock();
MutexGuard { lock }
}
fn get(&mut self) -> &mut T {
&mut *self.lock.t
}
}
impl<'a, T> Drop for MutexGuard<'a, T> {
fn drop(&mut self) {
self.lock.system_mutex.unlock();
}
}
struct Mutex<T> { /* same as before */ }
impl<T> Mutex<T> {
pub fn lock<'a>(&'a self) -> MutexGuard<'a, T> {
MutexGuard::new(self)
}
}
fn main() {
let mtx = Mutex::new(1);
{
let guard = mtx.lock();
let n = guard.get();
*n = 1;
}
{
let guard = mtx.lock();
let n = guard.get();
*n = 2;
}
}
Thise API now enforces both access control and cleanup:
- Access control: when a thread calls
MutexGuard::get, the borrow onTcan only last as long as theMutexGuard, preventing dangling pointers. And the mutex is guaranteed to be locked by construction whenMutexGuardexists. - Cleanup: only after all borrows to
Thave ended willMutexGuardbe dropped, which then automatically unlocks the system mutex. The API client cannot possibly forget or unlock in the wrong order.
For more examples, this pattern is used throughout the standard library: Mutex<T>, RwLock<T>, and RefCell<T>.
Closure guards
A variant on the guard design uses closures rather than guard structs. For example, a closure-based mutex:
struct Mutex<T> { /* same as before */ } impl<T> Mutex<T> { pub fn lock(&self, f: impl FnMut(&mut T)) { self.system_mutex.lock(); f(&mut self.t.get()); self.system_mutex.unlock(); } } fn main() { let mtx = Mutex::new(1); mtx.lock(|n| { *n = 1; }); mtx.lock(|n| { *n = 2; }); }
The use of closures enables an API to:
- Execute code at the right time (after the lock is taken)
- Pass the protected data to the code for a limited duration (
&mut T) - Regain control and cleanup after execution (unlocking the lock)
State Machines
Access control can be viewed as a special case of a state machine. For example, a mutex is a two-state machine:
State machines have two core concepts: states (the circles) and transitions (the arrows). When APIs represent state machines, the important question is whether the transitions are consistent with the states, e.g. you should not be able to unlock an unlocked mutex. Here are a few more examples of state machines in systems:
- A shopper can only checkout while their cart is not empty.
- A file can only be closed while its file descriptor is open.
- A GPIO pin can only be written to when in write mode.
Typestate
Let's say we're implementing an API for a read-only file. It should adhere to the following state machine:
A file is opened into a reading state, and is read until reaching the end-of-file (eof). In either state, the file can be closed. From the lens of access control, our API design goal is to only allow access to certain operations (eg read()) when an object is in a corresponding state (eg reading).
As a first attempt, here's a perfectly reasonable API that's similar to std::fs::File:
struct File {
reached_eof: bool,
/* .. */
}
impl File {
pub fn open(path: String) -> Option<File> { /* .. */ }
// Returns None if reached EOF
pub fn read(&mut self) -> Option<Vec<u8>> {
if self.reached_eof {
None
} else {
// read the file ..
}
}
pub fn close(self);
}
fn main() {
let mut f = File::open("test.txt".to_owned()).unwrap();
while let Some(bytes) = f.read() {
println!("{:?}", bytes);
}
f.read(); // This works! Just will return None
f.close();
}
The key question for this API: how does it prevent calling read() in an EOF state? Here, the answer is: it doesn't. Rather, calling read() after EOF is a runtime error, represented by the None branch of the Option type. The state machine is only contained internally (reached_eof).
Representing states as structs
Let's say the goal is to prevent the user from ever calling read() in an EOF state. That is, the call to f.read() after the while let should not compile in the first place. Now we arrive at the concept of typestate: encoding the states of the state machine into the type system.
// 1. Each state is its own struct
struct ReadingFile { inner: File }
struct EofFile { inner: File }
enum ReadResult {
Read(ReadingFile, Vec<u8>),
Eof(EofFile)
}
impl ReadingFile {
pub fn open(path: String) -> Option<ReadingFile> { /* .. */ }
// 2. Calling `read()` takes ownership of ReadingFile
pub fn read(self) -> ReadResult {
match self.inner.read() {
// 3. Access to `ReadingFile` is only given back if not at EOF
Some(bytes) => ReadResult::Read(self, bytes)
None => ReadResult::Eof(EofFile { inner: self.inner })
}
}
pub fn close(self) {
self.inner.close();
}
}
impl EofFile {
pub fn close(self) {
self.inner.close();
}
}
fn main() {
let mut file = ReadingFile::open("test.txt".to_owned()).unwrap();
loop {
match file.read() {
ReadResult::Read(f, bytes) => {
println!("{:?}", bytes);
file = f;
}
ReadResult::Eof(f) => {
f.close();
break;
}
}
}
// file has been moved, can't call file.read() here
}
This API design has three key ideas:
- Each state is a struct: the
ReadingFileandEofFilestates are represented as distinct structs. This way, we can associate different methods with each. - Each state has only its transitions implemented: the
read()method is implemented forReadingFile, but not forEofFile, while both can callclose(). - Transitions between states consume ownership: the
read()method consumesReadingFileand returns whichever state comes after. This prevents calling methods on an old state.
Moving states into a type parameter
One ugliness in this design is that the user has to manage a single logical object (the file) but split into multiple actual types (the states). An alternative design is to represent states as a type parameter to a single object, like so:
struct Reading;
struct Eof;
struct File2<State> {
inner: File,
_state: PhantomData<State>
}
enum ReadResult {
Read(File2<Reading>, Vec<u8>),
Eof(File2<Eof>)
}
impl File2<Reading> {
pub fn open(path: String) -> Option<File2<Reading>> { /* .. */ }
pub fn read(self) -> ReadResult {
match self.inner.read() {
// 3. Access to `ReadingFile` is only given back if not at EOF
Some(bytes) => ReadResult::Read(self, bytes)
None => ReadResult::Eof(File2 { inner: self.inner, _state: PhantomData })
}
}
pub fn close(self) {
self.inner.close();
}
}
impl File2<Eof> {
pub fn close(self) {
self.inner.close();
}
}
The API is largely the same, and the usage example from before still works. But on the implementation side, we now have to carry around this PhantomData marker or else Rust complains about an unused type parameter.
Further reading
State combinators
TODO: talk about session types
Parallel Lists
Another common pattern in system design is to have two lists of pairwise-related (or "parallel") elements. For example, consider println:
println!("#{:03} {}: {}", id, user, message);
The first list is the format directives (e.g. {}) in the format string. The second list is the inputs (e.g. id) to println!. These lists must have the same length.
As another example, consider routing in a web server:
#[route("/user/:id/messages/:message_id")]
fn user_message(id: Id, message_id: MessageId) {
/* .. /
}
The first list is the routing variables (e.g. :id) and the second is the function parameters (e.g. id: Id). These lists must have the same length and corresponding types.
I'll show you how to use heterogeneous lists (H-lists), or lists of values of different types, to implement APIs with parallel lists. Specifically, we will implement a type-safe printf. For a real-world example, you can check out how the warp framework uses H-lists to do type-safe web routing.
Core mechanism: HList
First, we need to understand H-lists. An H-list is a sequence of values of potentially different types. For example, [1, "a", true] is an H-list, but not a valid Rust vector. H-lists are implemented in Rust using a linked-list style:
struct HNil;
struct HCons<Head, Tail> {
head: Head,
tail: Tail
}
let example: HCons<i32, HCons<bool, HNil>> =
HCons{head: 1, tail: HCons{head: true, tail: HNil}};
The key idea is that the type of an H-list changes every time you make a change to it. By contrast, if you push to a Vec<T>, the type of the vector stays the same.
Just like Rust has vec![], we can use the frunk crate to get an hlist! macro.
let example = hlist![1, true]; // same as above
Setting up printf
Let's go back to the ingredients of printf. We need a format string and an argument list. The key idea is to represent both with an H-list, and carefully use Rust's traits to ensure our desired property: the number of arguments should match the number of holes.
First, to represent format strings, we will have a sequence of structs that represent each part of the string.
pub struct FString(&'static str);
pub struct FVar;
// Assume that we compile "Hello {}! The first prime is {}" into this code.
// That would be a simple syntactic transformation.
let example = hlist![
FString("Hello "), FVar, FString("! The first prime is "), FVar
];
To represent arguments, we will use a matching H-list of values. For example:
let args = hlist!["world", 2];
Then, our goal is to create a function format such that this is true:
assert_eq!(
example.format(args),
"Hello world! The first prime is 2"
);
And this should be a compile-time (NOT run-time) error:
example.format(hlist!["Only one arg"]);
The Format trait
First, we need to define the signature of our format function.
trait Format<ArgList> {
fn format(&self, args: ArgList) -> String;
}
Here, self is the H-list of the format directives, and ArgList is the H-list of the variadic arguments. Format need to take ArgList as a type parameter, because its type will change as we remove elements from the ArgList list.
Now, we proceed to implement the Format trait by cases. First, the base case for reaching the end of the format list HNil:
impl Format<HNil> for HNil {
fn format(&self, _args: HNil) -> String {
"".to_string()
}
}
This impl says that when we reach the end of a format list, just return the empty string. And the only argument we will accept is an empty argument list. Combined with the next impls, this inductively ensures that extra arguments are not accepted.
Next, we will implement FString. This implementation should use the string constant contained in the FString struct, and combine it recursively with the rest of the format list. We don't use variadic arguments for FString, so they get passed along. In Rust, this English specification becomes:
impl<ArgList, FmtList> Format<ArgList>
for HCons<FString, FmtList>
where FmtList: Format<ArgList>
{
fn format(&self, args: ArgList) -> String {
self.head.0.to_owned() + &self.tail.format(args)
}
}
Note that we have to add FmtList: Format<ArgList> to ensure the recursive call to self.tail.format works. Also note that we aren't implementing Format directly on FString, but rather on an H-list containing FString.
Finally, the most complex case, FVar. We want this impl to take an argument from the ArgList, then format the remaining format list with the remaining arguments.
impl<T, ArgList, FmtList> Format<HCons<T, ArgList>>
for HCons<FVar, FmtList>
where
FmtList: Format<ArgList>,
T: ToString,
{
fn format(&self, args: HCons<T, ArgList>) -> String {
args.head.to_string() + &self.tail.format(args.tail)
}
}
Be careful to observe which H-list is being accessed by head and tail. Here, the args H-list provides the data to fill the hole via args.head.
Checking our properties
With this implementation, our correct example successfully compiles and runs:
let example = hlist![
FString("Hello "), FVar, FString("! The first prime is "), FVar
];
assert_eq!(
example.format(hlist!["world", 2]),
"Hello world! The first prime is 2"
);
What about our incorrect example? If we write this:
example.format(hlist!["just one arg"]);
This code fails to compile with the error:
error[E0308]: mismatched types
--> src/printf.rs:48:18
|
48 | example.format(hlist!["just one arg"]);
| ^^^^^^^^^^^^^^^^^^^^^^
| expected struct `Cons`, found struct `HNil`
|
= note: expected struct `HCons<_, HNil>`
found struct `HNil`
While the error is enigmatic, our mistake is at least correctly caught at compile-time. This is because Rust deduces that example.format() expects an H-list of the shape HCons<_, HCons<_, HNil>>, but it finds HNil too soon in our 1-element H-list. A similar error occurs when providing too many args.
Stupendous! We have successfully implemented a type-safe printf using H-lists and traits.
Extending our abstraction
Right now, our Format function just checks that the format list and argument list are the same length. We could extend our format structures, for example to ensure that an FVar must be a particular type, or must use Debug vs. Display. Here's the sketch of such a strategy:
use std::marker::PhantomData;
// Add flags for whether using Display or Debug
pub struct FDisplay;
pub struct FDebug;
// Use a type parameter with PhantomData to represent the intended type
pub struct FVar<T, Flag>(PhantomData<(T, Flag)>);
// Now, T has to be the same between the format list and arg list
// Also, FDisplay flag requires that `T: Display`
impl<T, ArgList, FmtList> Format<HCons<T, ArgList>>
for HCons<FVar<T, FDisplay>, FmtList>
where
FmtList: Format<ArgList>,
T: Display,
{
fn format(&self, args: HCons<T, ArgList>) -> String {
// using format! is cheating, but you get the idea
format!("{}", args) + &self.tail.format(args.tail)
}
}
// Similar impl for `T: Debug` when `FDebug` is used
With this approach, if our format list and arg list differ in type:
let fmt = hlist![FString("n: "), FVar::<i32, FDisplay>(PhantomData)];
fmt.format(hlist!["not a number"]);
Then the code will not compile with the error, &'static str is not i32.
Registries
Extensible systems, or frameworks where the client plugs in their own functionality, often have a notion of "registration" to associate the user's code with a piece of the framework. For example:
- In event systems, users can register callbacks to be triggered when an event occurs.
- In dependency injection systems, users register dependencies which gets plumbed to other code that is registered to request that dependency.
These systems use registries to maintain sets of event listeners or dependencies. The key API design challenge is to maintain consistency between the registered objects and the code that reads the registry. As a running example, we will use an event system. Consider this API that works like JavaScript's addEventListener:
use std::any::Any; use std::collections::HashMap; type EventListener = Box<dyn Fn(&dyn Any)>; #[derive(Default)] struct EventRegistry { listeners: HashMap<String, Vec<EventListener>> } impl EventRegistry { fn add_event_listener(&mut self, event: String, f: EventListener) { self.listeners.entry(event).or_insert_with(Vec::new).push(f); } fn trigger(&self, event: String, data: &dyn Any) { let listeners = self.listeners.get(&event).unwrap(); for listener in listeners.iter() { listener(data); } } } struct OnClick { mouse_x: f32, mouse_y: f32 } fn main() { let mut events = EventRegistry::default(); events.add_event_listener("click".to_owned(), Box::new(|event| { let event = event.downcast_ref::<OnClick>().unwrap(); assert_eq!(event.mouse_x, 1.); })); let event = OnClick { mouse_x: 1., mouse_y: 3. }; events.trigger("click".to_owned(), &event); }
How could a user incorrectlmouse_y work with this API? They could:
-
Typo the event name: as with all stringly-typed programming, the event name could be the wrong string, like
"clack"instead of"click", for either the listener or the trigger. -
Send the wrong payload for an event: event listeners take literally any type as input. A user could trigger a
MouseEventfor the"click"string. -
Use the event payload incorrectly:: a user could incorrectly cast the payload to
MouseEventfor a listener to the"click"event.
The core issue is that the event name "click" and the event data OnClick are linked by convention but not by design. This issue is inherent to registries that use strings to identify objects.
Instead, I will show you how to design both an event system and a dependency injection system using types as keys intead of strings as keys. Type-based registries will avoid all of the issues in the API above.
1. Type-safe events
Our goal is to write an API that looks like this from the client's perspective:
struct OnClick {
mouse_x: f32,
mouse_y: f32,
}
let mut events = EventRegistry::new();
// The event is passed in as a type parameter instead of a string
events.add_event_listener::<OnClick>(|event| {
assert_eq!(event.mouse_x, 10.);
assert_eq!(event.mouse_y, 5.);
});
// The event type could alternatively be inferred from the closure
events.add_event_listener(|event: &OnClick| {
assert_eq!(event.mouse_x, 10.);
assert_eq!(event.mouse_y, 5.);
});
events.trigger(&OnClick {
mouse_x: 10.,
mouse_y: 5.,
})
The outline of the underlying API looks like this:
trait Event = 'static;
trait EventListener<E> = Fn(&E) -> () + 'static;
struct EventRegistry { /* .. */ };
impl EventRegistry {
fn add_event_listener<E: Event>(
&mut self,
f: impl EventListener<E>
) {
/* .. */
}
fn trigger<E: Event>(
&self,
event: &E
) {
/* .. */
}
}
Each method on the event registry takes an event type E as input, rather than a string key. The registry associates listeners with that type, and then looks up listeners with that type.
Mapping types to values
To associate values (e.g. event listeners) with types, we will make a core building block: the TypeMap.
Rust has std::any for this purpose. TypeId allows us to get a unique, hashable identifier for each type. Any allows us to up-cast/down-cast objects at runtime. Hence, our TypeMap will map from TypeId to Box<dyn Any>.
use std::collections::HashMap;
use std::any::{TypeId, Any};
struct TypeMap(HashMap<TypeId, Box<dyn Any>>);
To add an element to the map:
impl TypeMap {
pub fn set<T: Any + 'static>(&mut self, t: T) {
self.0.insert(TypeId::of::<T>(), Box::new(t));
}
}
This means our map has one unique value for a given type. For example, if we use the TypeMap like this:
let mut map = TypeMap::new();
map.set::<i32>(1);
Aside: the syntax
::<i32>is Rust's "turbofish". It explicitly binds a type parameter of a polymorphic function, rather than leaving it to be inferred. Further explanation here.
Then we insert a value 1 at the key TypeId::of::<i32>(). We can also implement has and get functions:
impl TypeMap {
pub fn has<T: Any + 'static>(&self) -> bool {
self.0.contains_key(&TypeId::of::<T>())
}
pub fn get_mut<T: Any + 'static>(&mut self) -> Option<&mut T> {
self.0.get_mut(&TypeId::of::<T>()).map(|t| {
t.downcast_mut::<T>().unwrap()
})
}
}
Look carefully at get_mut. The inner hash map returns a value of type Box<dyn Any>, which we can downcast_mut to become a value of type &mut T. This operation is guaranteed to not fail, because only values of type T are stored in the hash map under the key for T.
Implementing the event system
With the TypeMap in hand, we can finish our event system. For the EventRegistry, the TypeMap will map from events to a vector of listeners.
struct EventDispatcher(TypeMap);
type ListenerVec<E> = Vec<Box<dyn EventListener<E>>>;
impl EventDispatcher {
fn add_event_listener<E>(&mut self, f: impl EventListener<E>) {
if !self.0.has::<ListenerVec<E>>() {
self.0.set::<ListenerVec<E>>(Vec::new());
}
let listeners = self.0.get_mut::<ListenerVec<E>>().unwrap();
listeners.push(Box::new(f));
}
fn trigger<E>(&self, event: &E) {
if let Some(listeners) = self.0.get::<ListenerVec<E>>() {
for callback in listeners {
callback(event);
}
}
}
}
Returning to our API design goals, this design enforces consistency between related elements: an event listener's payload must match the event it's registered to.
2. Type-safe dependency injection
We'll walk through another example of using type registries to avoid unsafe string-based design. The basic idea of dependency injection (DI) is that you have a component that depends on another, like a web server using a database. However, you don't want to hard-code a particular database constructor, and rather make it easy to swap in different databases. For example:
trait Database {
fn name(&self) -> &'static str;
}
struct MySQL;
impl Database for MySQL {
fn name(&self) -> &'static str { "MySQL" }
}
struct Postgres;
impl Database for Postgres {
fn name(&self) -> &'static str { "Postgres" }
}
struct WebServer { db: Box<dyn Database> }
impl WebServer {
fn run(&self) {
println!("Db name: {}", self.db.name());
}
}
To implement DI, we need two things:
- We need a way to register a global
Databaseat runtime to a particular instance, e.g.MySQLorPostgres. - We need a way to describe a constructor for
WebServerthat fetches the registeredDatabaseinstance.
With these pieces, we can use our DI system like so:
let mut manager = DIManager::new();
manager.build::<MySQL>().unwrap();
let server = manager.build::<WebServer>().unwrap();
server.lock().unwrap().run(); // prints Db name: MySQL
DI constructors
First, we'll define a trait DIBuilder that represents a constructor within our DI system.
trait DIBuilder {
type Input;
type Output;
fn build(input: Self::Input) -> Self::Output;
}
The build method is a static method (doesn't take self as input). It just takes Input as input, and produces Output as output. The key idea is that because Input and Output are associated types, we can inspect them later on. We will need to find values for Input and to store Output in our DI manager.
We implement DIBuilder for each type in the system. The databases have no inputs, so their input is (). Their return type is Box<dyn Database>, meaning they are explicitly cast to a trait object so they can be used interchangeably.
impl DIBuilder for MySQL {
type Input = ();
type Output = Box<dyn Database>;
fn build((): ()) -> Box<dyn Database> {
Box::new(MySQL)
}
}
impl DIBuilder for Postgres {
type Input = ();
type Output = Box<dyn Database>;
fn build((): ()) -> Box<dyn Database> {
Box::new(Postgres)
}
}
impl DIBuilder for WebServer {
type Input = (Box<dyn Database>,);
type Output = WebServer;
fn build((db,): Self::Input) -> WebServer {
WebServer { db }
}
}
DI manager
Now that we know the dependency structure of our objects, we need a centralized manager to store the objects and fetch their dependencies.
struct DIManager(TypeMap);
In this TypeMap, we will store the constructed objects. For example, once we make a Box<dyn Database>, then we will map TypeId::of::<Box<dyn Database>> to one of Box<Postgres> or Box<MySQL>.
impl DIManager {
fn build<T: DIBuilder>(&mut self) -> Option<T::Output> {
let input = /* get the inputs, somehow */;
let obj = T::build(input);
self.0.set::<T::Output>(obj);
Some(obj)
}
}
Ignoring how we fetch dependencies for now, this function calls the DIBuilder::build implementation for T, then stores the result in the TypeMap. This approach almost works, except not for Rust: ownership of obj is passed into TypeMap and the result of build.
And, intuitively, this makes sense. If a component like a database cursor needs to be shared across many downstream components, it needs some kind of access protection. Hence, we tweak our interface a bit to wrap everything in an Arc and Mutex.
type DIObj<T> = Arc<Mutex<T>>;
impl DIManager {
fn build<T: DIBuilder>(&mut self) -> Option<DIObj<T::Output>> {
let input = /* get the inputs, somehow */;
let obj = T::build(input);
let sync_obj = Arc::new(Mutex::new(obj));
self.0.set::<DIObj<T::Output>>(sync_obj.clone());
Some(sync_obj)
}
}
DI dependencies
Finally, we need a way to implement the let input line in DIManager::build. Given a type T: DIBuilder, it has an associated type T::Input that represents the inputs needed to build it.
To simplify the problem, imagine T::Input = S where S: DIBuilder. Then if S has already been built, e.g. T = WebServer and S = Box<dyn Database>, we can fetch it directly from the typemap:
let input = self.0.get::<T::Input>().map(|obj| obj.clone())?;
However, in practice T::Input could be several dependencies. For example, if our server depends on a configuration, it might be:
impl DIBuilder for WebServer {
type Input = (Box<dyn Database>, Box<dyn ServerConfig>);
type Output = WebServer;
fn build((db, config): Self::Input) -> WebServer {
WebServer { db, config }
}
}
Let's assume now T::Input is always a tuple (S1, S2, ...) of types where each type Si : DIBuilder. Ideally, we could write something like:
let input = (T::Input).map(|S| {
self.0.get::<S>().map(|obj| obj.clone()).unwrap()
});
But, alas, our language of expressions is not our language of types. Such a thing is the provenance of languages we can only dream about. Instead, we have to cleverly use traits to inductively define a way to extract inputs from the tuple. To start, we'll make a trait that gets an object of a particular type from the DIManager:
trait GetInput: Sized {
fn get_input(manager: &DIManager) -> Option<Self>;
}
For DIObj<T>, this means looking up the type in the TypeMap:
impl<T: 'static> GetInput for DIObj<T> {
fn get_input(manager: &DIManager) -> Option<Self> {
manager.0.get::<Self>().map(|obj| obj.clone())
}
}
Then for tuples of DIObj<T>, we can make an inductive definition like so:
impl GetInput for () {
fn get_input(_manager: &DIManager) -> Option<Self> {
Some(())
}
}
impl<S: GetInput, T: GetInput> GetInput for (S, T) {
fn get_input(manager: &DIManager) -> Option<Self> {
S::get_input(manager).and_then(|s| {
T::get_input(manager).and_then(|t| {
Some((s, t))
})
})
}
}
Then we can modify our WebServer example to use an inductive structure:
impl DIBuilder for WebServer {
type Input = (DIObj<Box<dyn Database>>,(DIObj<Box<dyn ServerConfig>>,()));
type Output = WebServer;
fn build((db, (config, ())): Self::Input) -> WebServer {
WebServer { db, config }
}
}
Aside: in practice, rather than doing nested pairs, you can use a macro to create the
GetInputimpl for many tuple types like this.
And at last, we can implement DIManager::build:
impl DIManager {
pub fn build<T: DIBuilder>(&mut self) -> Option<DIObj<T::Output>> {
let input = T::Input::get_input(self)?;
let obj = T::build(input);
let sync_obj = Arc::new(Mutex::new(obj));
self.0.set::<DIObj<T::Output>>(sync_obj.clone());
Some(sync_obj)
}
}
Now, the expression T::Input::get_input(self) will convert a tuple of types into a tuple of values of those types.
Final API example
With the API complete, our example now looks like this:
let mut manager = DIManager::new();
manager.build::<MySQL>().unwrap();
let server = manager.build::<WebServer>().unwrap();
server.lock().unwrap().run();
We can construct a WebServer without explicitly passing in a dyn Database instance. When we use the server, we have to explicitly call .lock() now that it's wrapped in a mutex. And lo, our dependencies have been injected.